Table of Contents
TL;DR: Efficient C# File Processing Strategies
- Prevent system crashes: Avoid naive parallel processing that launches thousands of concurrent file operations.
- Optimize throughput: Use
SemaphoreSlimto control concurrency (start with 2x CPU cores) for balanced performance. - Reduce memory consumption: Implement true async I/O with
useAsync: trueand process files line-by-line instead of loading them entirely. - Minimize database overhead: Batch related records from multiple files before making database calls.
- Maximize system resources: For production systems, implement adaptive throttling that responds to CPU/memory conditions.
- Leverage modern C# features: Use
IAsyncEnumerablefor efficient streaming and TPL Dataflow for complex processing pipelines.
Ever tried to build an import tool that needs to process thousands of CSV files at once? I have, and I learned the hard way that simply starting a thousand file operations simultaneously is a recipe for disaster.
Let’s talk about how to handle this real-world problem in C#. I’ll show you some practical ways to process huge batches of files without bringing your system to its knees. We’ll look at how to use tools like SemaphoreSlim and Task.WhenAll, plus some smart ways to handle async file operations.
Understanding the File Processing Challenge
Before diving into solutions, let’s understand what makes high-volume file processing difficult:
Operating System Limits: Windows and Linux have built-in limits on open file handles (typically a few thousand). Exceed these, and your application crashes.
Memory Constraints: Loading thousands of large files into memory simultaneously can exhaust available RAM.
I/O Bottlenecks: Even with fast SSDs, there’s a physical limit to how many simultaneous read/write operations a disk can handle efficiently.
Thread Pool Saturation: Too many asynchronous operations can overwhelm the .NET thread pool, affecting your entire application’s performance.
Resource Contention: Processes competing for the same resources (CPU, disk, memory) can cause thrashing and degraded performance.
The right approach balances parallel processing for speed while respecting these limitations. Let’s explore what happens when we ignore these constraints, and then build progressively better solutions.
flowchart LR
Start([Thousands of Files<br>Need Processing]) --> Choice{"Choose a<br>Processing Strategy"}
Choice -->|"Approach 1"| Sequential["Sequential Processing<br>One File at a Time"]
Choice -->|"Approach 2"| Naive["Naive Parallelism<br>All Files at Once"]
Choice -->|"Approach 3"| Throttled["Throttled Parallelism<br>with SemaphoreSlim"]
Choice -->|"Approach 4"| Adaptive["Adaptive Throttling<br>with Resource Monitoring"]
Sequential --> SeqPerf["✓ Simple Code<br>✓ Low Memory Usage<br>✓ No Crashes<br>✗ Very Slow<br>✗ Poor Resource Utilization"]
Naive --> NaivePerf["✓ Simple Code<br>✓ Potentially Fastest<br>✗ System Crashes<br>✗ Out of Memory<br>✗ Too Many Open Files"]
Throttled --> ThrottledPerf["✓ Good Performance<br>✓ Controlled Resource Usage<br>✓ Predictable Behavior<br>✓ Scales with Hardware<br>✗ Requires Tuning"]
Adaptive --> AdaptivePerf["✓ Optimal Performance<br>✓ Self-tuning<br>✓ Handles Variable Workloads<br>✓ Adapts to System Load<br>✗ More Complex Implementation"]
%% Additional processing methods
subgraph "Processing Implementation Options"
direction TB
ReadAll["Read Entire File<br>ReadAllTextAsync"] -->|"For Small Files"| ThrottledPerf
StreamRead["Line by Line<br>ReadLineAsync"] -->|"For Medium Files"| ThrottledPerf
AsyncEnum["IAsyncEnumerable<br>True Streaming"] -->|"For Large Files"| ThrottledPerf
MemoryMapped["Memory-Mapped Files"] -->|"For Very Large Files"| ThrottledPerf
end
%% High-level techniques
subgraph "Advanced Implementation Techniques"
direction TB
Batching["Database Batching<br>Save Multiple Files at Once"]
Chunking["Process in Chunks<br>Control Memory Usage"]
Pipeline["TPL Dataflow<br>Processing Pipeline"]
ConcLimit["Concurrency Limits<br>Based on Hardware"]
end
ThrottledPerf --> Batching
ThrottledPerf --> ConcLimit
AdaptivePerf --> Chunking
AdaptivePerf --> Pipeline
class Sequential fill:#ffcccc,stroke:#333,stroke-width:1px
class Naive fill:#ffcccc,stroke:#333,stroke-width:1px
class Throttled fill:#ccffcc,stroke:#333,stroke-width:1px
class Adaptive fill:#ccffcc,stroke:#333,stroke-width:1px
class ThrottledPerf,AdaptivePerf fill:#d0f0c0,stroke:#333
class NaivePerf fill:#ffb6b6,stroke:#333
class SeqPerf fill:#ffffb6,stroke:#333
File Processing Strategies: Performance vs. System Stability
What Goes Wrong When Processing Thousands of Files
When you’re building a tool to import thousands of CSV files, you might start with something like this:
public async Task ProcessAllFilesNaively(List<string> filePaths)
{
var tasks = new List<Task>();
foreach (var path in filePaths)
{
tasks.Add(ProcessFileAsync(path));
}
await Task.WhenAll(tasks);
}
private async Task ProcessFileAsync(string path)
{
using var reader = new StreamReader(path);
var content = await reader.ReadToEndAsync();
// Process content...
}
This looks simple enough, but it falls apart quickly when you throw 5,000 files at it:
Your OS will scream at you: Operating systems limit how many files you can have open at once. Hit that limit and you get crashes.
Your memory usage explodes: With each file read loading the entire content into memory, RAM gets eaten up fast.
Your disk gets hammered: Physical disks (even SSDs) struggle when hit with too many random read operations at once.
The thread pool gets swamped: Too many I/O operations can actually block other parts of your application from getting work done.
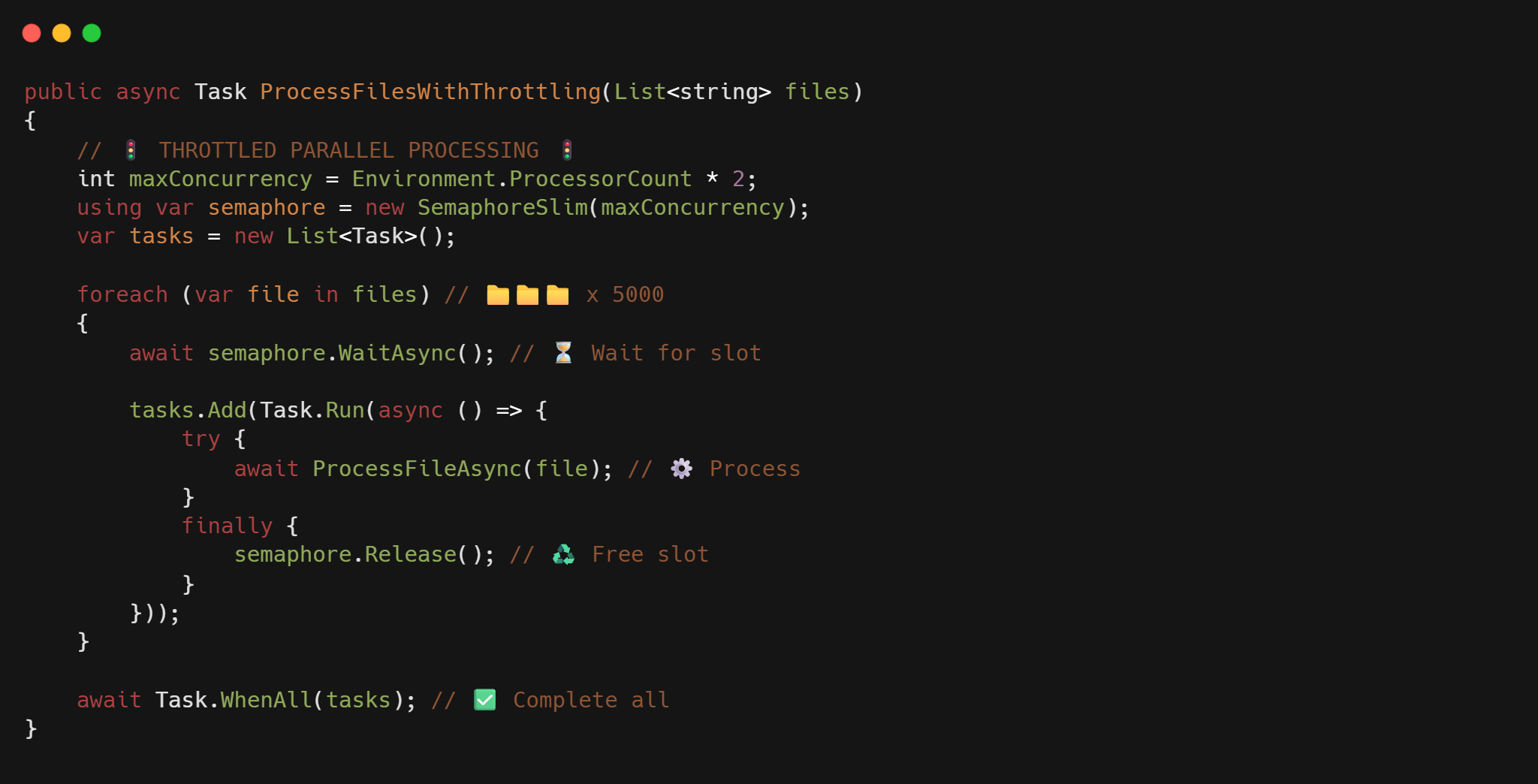
Throttling with SemaphoreSlim: The Traffic Cop for Your Tasks
The secret to handling loads of files is to limit how many you process at once. That’s where SemaphoreSlim comes in, think of it as a traffic cop for your tasks:
public async Task ProcessFilesWithSemaphore(List<string> filePaths)
{
// Process about 2 files per CPU core at once
int maxConcurrency = Environment.ProcessorCount * 2;
using var semaphore = new SemaphoreSlim(maxConcurrency);
var tasks = new List<Task>();
foreach (var path in filePaths)
{
await semaphore.WaitAsync(); // Wait for an open slot
tasks.Add(Task.Run(async () =>
{
try
{
await ProcessFileAsync(path);
}
finally
{
semaphore.Release(); // Always release when done!
}
}));
}
await Task.WhenAll(tasks);
}
This approach limits the number of concurrent file operations to a manageable level (here, twice the number of processor cores). The SemaphoreSlim acts as a gatekeeper, ensuring we don’t overwhelm system resources.
Better Ways to Read Files
Just controlling how many files we process isn’t enough. We also need to be smart about how we read each file:
private async Task ProcessFileAsync(string path)
{
// Set up a proper async stream
using var fileStream = new FileStream(
path,
FileMode.Open,
FileAccess.Read,
FileShare.Read,
bufferSize: 4096,
useAsync: true); // This flag makes a huge difference!
using var reader = new StreamReader(fileStream);
// Process one line at a time instead of the whole file
string line;
while ((line = await reader.ReadLineAsync()) != null)
{
await ProcessCsvLineAsync(line);
}
}
Here’s what makes this approach better:
- The
useAsync: trueflag tells .NET to use truly non-blocking I/O operations - Reading line by line avoids loading entire files into memory at once
- The 4096-byte buffer size works well for most scenarios (it matches common disk page sizes)
Leveling Up with IAsyncEnumerable in .NET Core 3.0+
Starting with .NET Core 3.0, we got a powerful new tool for working with asynchronous data: IAsyncEnumerable<T>. This interface lets us stream data asynchronously using await foreach, creating a true asynchronous pipeline for processing files.
Here’s how we can refactor our file reader to leverage this approach:
public async IAsyncEnumerable<CsvRecord> ReadFileLinesAsync(string path)
{
using var fileStream = new FileStream(
path,
FileMode.Open,
FileAccess.Read,
FileShare.Read,
bufferSize: 4096,
useAsync: true);
using var reader = new StreamReader(fileStream);
// Skip header
await reader.ReadLineAsync();
// Stream records one by one
string line;
while ((line = await reader.ReadLineAsync()) != null)
{
if (string.IsNullOrWhiteSpace(line)) continue;
yield return ParseCsvLine(line);
}
}
And here’s how to use it:
public async Task ProcessFileAsync(string path)
{
var records = new List<CsvRecord>();
await foreach (var record in ReadFileLinesAsync(path))
{
// Process each record as it arrives, without waiting for the entire file
records.Add(record);
// Optionally process in batches to minimize DB calls
if (records.Count >= 1000)
{
await SaveRecordsAsync(records);
records.Clear();
}
}
// Save any remaining records
if (records.Any())
{
await SaveRecordsAsync(records);
}
}
Benefits of Using IAsyncEnumerable
- True Streaming: You process data as it arrives, not waiting for an entire collection.
- Memory Efficiency: You’re never holding the entire file contents in memory.
- Backpressure Support: The consumer’s pace naturally controls how fast data is read.
- Composition: You can easily chain multiple async operations in a pipeline.
IAsyncEnumerable with SemaphoreSlim
Let’s combine our throttling approach with IAsyncEnumerable for a comprehensive solution:
public class ModernCsvBatchProcessor
{
private readonly int _maxConcurrency;
private readonly IDataImportService _importService;
public ModernCsvBatchProcessor(IDataImportService importService, int? maxConcurrency = null)
{
_importService = importService;
_maxConcurrency = maxConcurrency ?? Environment.ProcessorCount * 2;
}
public async Task<BatchImportResult> ImportFilesAsync(IEnumerable<string> filePaths,
IProgress<int> progress = null)
{
using var semaphore = new SemaphoreSlim(_maxConcurrency);
var tasks = new List<Task<FileImportResult>>();
var result = new BatchImportResult
{
FileResults = new List<FileImportResult>()
};
int completedFiles = 0;
int totalFiles = filePaths.Count();
foreach (var path in filePaths)
{
await semaphore.WaitAsync();
tasks.Add(Task.Run(async () =>
{
try
{
var fileResult = await ProcessSingleFileAsync(path);
// Report progress if requested
Interlocked.Increment(ref completedFiles);
progress?.Report((int)(100.0 * completedFiles / totalFiles));
return fileResult;
}
finally
{
semaphore.Release();
}
}));
}
var results = await Task.WhenAll(tasks);
// Summarize the results
result.SuccessCount = results.Count(r => r.Success);
result.FailureCount = results.Count(r => !r.Success);
result.FileResults = results.ToList();
return result;
}
private async Task<FileImportResult> ProcessSingleFileAsync(string path)
{
try
{
var records = new List<CsvRecord>();
int lineNumber = 1; // Start at 1 for header
try
{
await foreach (var record in ReadFileLinesAsync(path))
{
lineNumber++;
records.Add(record);
}
// Save all records from this file in one go
await _importService.SaveRecordsAsync(records);
return new FileImportResult
{
FileName = Path.GetFileName(path),
Success = true,
RecordsProcessed = records.Count
};
}
catch (Exception ex)
{
return new FileImportResult
{
FileName = Path.GetFileName(path),
Success = false,
Error = $"Error parsing line {lineNumber}: {ex.Message}"
};
}
}
catch (Exception ex)
{
return new FileImportResult
{
FileName = Path.GetFileName(path),
Success = false,
Error = ex.Message
};
}
}
private async IAsyncEnumerable<CsvRecord> ReadFileLinesAsync(string path)
{
using var fileStream = new FileStream(
path,
FileMode.Open,
FileAccess.Read,
FileShare.Read,
bufferSize: 4096,
useAsync: true);
using var reader = new StreamReader(fileStream);
// Skip header
await reader.ReadLineAsync();
string line;
while ((line = await reader.ReadLineAsync()) != null)
{
if (string.IsNullOrWhiteSpace(line)) continue;
yield return ParseCsvLine(line);
}
}
private CsvRecord ParseCsvLine(string line)
{
// You'd want a real CSV parser in production!
var parts = line.Split(',');
return new CsvRecord
{
Id = int.Parse(parts[0]),
Name = parts[1],
Value = decimal.Parse(parts[2])
};
}
}
This implementation includes:
- A configurable concurrency limit
- Proper error handling for both file-level and record-level errors
- A result tracking system to report success and failure counts
- Efficient file reading using async I/O
Here’s a visualization of the complete CSV batch processing workflow:
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ CSV Files │───▶ │ SemaphoreSlim│───▶│ Task Queue │
└───────────────┘ │ (Throttling) │ └───────┬───────┘
└───────────────┘ │
▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Result Summary│◀────│ Error Handling│◀───│ File Processor│
└───────────────┘ │ & Collection │ │ (per file) │
└───────────────┘ └───────┬───────┘
│
▼
┌───────────────┐ ┌───────────────┐
│ Database │◀─── │ Record │
│ Storage │ │ Collection │
└───────────────┘ └───────────────┘
Building Advanced Processing Pipelines with TPL Dataflow
For more complex file processing scenarios, you might need a full processing pipeline with different stages. That’s where TPL Dataflow shines. It allows you to create a network of processing blocks with built-in throttling, buffering, and linking capabilities.
Basic TPL Dataflow Pipeline
Here’s how to implement a file processing pipeline with TPL Dataflow:
public class DataflowFilePipeline
{
private readonly ExecutionDataflowBlockOptions _readOptions;
private readonly ExecutionDataflowBlockOptions _processOptions;
private readonly ExecutionDataflowBlockOptions _saveOptions;
private readonly ITargetBlock<string> _pipeline;
public DataflowFilePipeline(int maxConcurrentReads = 8, int maxConcurrentProcessing = 16, int maxConcurrentSaves = 4)
{
// Configure options for each stage
_readOptions = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = maxConcurrentReads,
BoundedCapacity = maxConcurrentReads * 2
};
_processOptions = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = maxConcurrentProcessing,
BoundedCapacity = maxConcurrentProcessing * 2
};
_saveOptions = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = maxConcurrentSaves,
BoundedCapacity = maxConcurrentSaves * 2
};
// Create the pipeline blocks
var readBlock = new TransformBlock<string, FileData>(
ReadFileAsync, _readOptions);
var processBlock = new TransformBlock<FileData, ProcessedData>(
ProcessFileDataAsync, _processOptions);
var saveBlock = new ActionBlock<ProcessedData>(
SaveToDbAsync, _saveOptions);
// Link the blocks
var linkOptions = new DataflowLinkOptions { PropagateCompletion = true };
readBlock.LinkTo(processBlock, linkOptions);
processBlock.LinkTo(saveBlock, linkOptions);
// Store the head of the pipeline
_pipeline = readBlock;
}
public async Task ProcessFilesAsync(IEnumerable<string> filePaths)
{
foreach (var path in filePaths)
{
await _pipeline.SendAsync(path);
}
// Signal that we're done adding files
_pipeline.Complete();
// Wait for the pipeline to finish processing
await ((IDataflowBlock)_pipeline).Completion;
}
private async Task<FileData> ReadFileAsync(string path)
{
try
{
using var fileStream = new FileStream(
path,
FileMode.Open,
FileAccess.Read,
FileShare.Read,
bufferSize: 4096,
useAsync: true);
using var reader = new StreamReader(fileStream);
var content = await reader.ReadToEndAsync();
return new FileData
{
FilePath = path,
Content = content,
Success = true
};
}
catch (Exception ex)
{
return new FileData
{
FilePath = path,
Error = ex.Message,
Success = false
};
}
}
private async Task<ProcessedData> ProcessFileDataAsync(FileData fileData)
{
if (!fileData.Success)
{
return new ProcessedData
{
FilePath = fileData.FilePath,
Success = false,
Error = fileData.Error
};
}
try
{
var records = new List<CsvRecord>();
using var reader = new StringReader(fileData.Content);
// Skip header
await reader.ReadLineAsync();
string line;
while ((line = await reader.ReadLineAsync()) != null)
{
if (string.IsNullOrWhiteSpace(line)) continue;
var record = ParseCsvLine(line);
records.Add(record);
}
return new ProcessedData
{
FilePath = fileData.FilePath,
Records = records,
Success = true
};
}
catch (Exception ex)
{
return new ProcessedData
{
FilePath = fileData.FilePath,
Success = false,
Error = ex.Message
};
}
}
private async Task SaveToDbAsync(ProcessedData data)
{
if (!data.Success || data.Records == null || !data.Records.Any())
return;
try
{
// Save to database in batches
foreach (var batch in CreateBatches(data.Records, 1000))
{
await _dbContext.BulkInsertAsync(batch);
}
Console.WriteLine($"Successfully processed {data.FilePath} with {data.Records.Count} records");
}
catch (Exception ex)
{
Console.WriteLine($"Error saving {data.FilePath}: {ex.Message}");
}
}
private CsvRecord ParseCsvLine(string line)
{
// Simple parsing logic as before
var parts = line.Split(',');
return new CsvRecord
{
Id = int.Parse(parts[0]),
Name = parts[1],
Value = decimal.Parse(parts[2])
};
}
private IEnumerable<List<T>> CreateBatches<T>(List<T> source, int batchSize)
{
for (int i = 0; i < source.Count; i += batchSize)
{
yield return source.GetRange(i, Math.Min(batchSize, source.Count - i));
}
}
// Data classes for pipeline stages
private class FileData
{
public string FilePath { get; set; }
public string Content { get; set; }
public bool Success { get; set; }
public string Error { get; set; }
}
private class ProcessedData
{
public string FilePath { get; set; }
public List<CsvRecord> Records { get; set; }
public bool Success { get; set; }
public string Error { get; set; }
}
}
Benefits of TPL Dataflow
TPL Dataflow offers several advantages for complex processing scenarios:
- Built-in throttling - Each block can have its own parallelism limit
- Back-pressure handling - Blocks can limit their input buffer, causing upstream blocks to slow down when needed
- Clean separation of concerns - Each stage focuses on one aspect of processing
- Flexible topologies - You can create complex processing networks, not just linear pipelines
- Fine-grained error handling - Each block can handle errors independently
When to Use TPL Dataflow
Consider using TPL Dataflow when:
- Your processing has clearly defined stages that can operate at different rates
- You need different concurrency limits for different operations
- You have complex routing logic (e.g., some files go through additional validation)
- Memory pressure is a concern and you need controlled buffering between stages
For simpler scenarios, the SemaphoreSlim approach might be more straightforward, but TPL Dataflow shines as complexity increases.
How Different Approaches Stack Up
Let’s see how the different ways of handling multiple files compare:
| Approach | Pros | Cons |
|---|---|---|
| One at a time | Dead simple code, uses minimal resources | Painfully slow with lots of files |
| All at once | Fastest in theory | Can crash your app with “Too many open files” or memory errors |
| Controlled parallelism (SemaphoreSlim) | Good speed without crashing | Takes a bit more code to implement right |
| TPL Dataflow | Flexible pipeline with fine-grained control | More complex to set up initially |
| IAsyncEnumerable | True streaming with minimal memory usage | Requires .NET Core 3.0+ or .NET 5+ |
| Memory-mapped files | Excellent for very large files | Adds complexity for simple operations |
Expected Performance Characteristics
While exact numbers will vary based on your hardware, file sizes, and specific processing needs, here’s what you can generally expect:
Controlled parallelism wins: The sweet spot varies by hardware, but limiting concurrency typically delivers the best reliable performance across different systems.
Adaptive throttling helps with variable workloads: When dealing with changing system conditions or mixed file sizes, adaptive throttling can maintain consistent performance.
Memory usage varies by approach: Naive approaches can consume gigabytes of RAM, while streaming approaches stay much leaner.
Storage type matters: SSDs can handle more concurrent operations than HDDs. Adjust your concurrency accordingly.
Tweaking for Better Performance
Here are some simple adjustments that can make a big difference:
Match your hardware: Different storage types can handle different loads. SSDs can usually take more parallel operations:
// SSDs can handle more parallel reads
int maxConcurrency = isSsd ? Environment.ProcessorCount * 8 : Environment.ProcessorCount * 2;
Buffer size matters: For big files, bigger buffers often help:
// Bigger buffer for reading larger files
const int largerBuffer = 8192; // or 16384 for really big files
using var fileStream = new FileStream(path, FileMode.Open, FileAccess.Read,
FileShare.Read, bufferSize: largerBuffer, useAsync: true);
Batch database work: Never make one database call per file, batch them up:
// Read all the files first
var allRecords = await Task.WhenAll(filePaths.Select(async path =>
{
// Get records from each file
return await ExtractRecordsFromFileAsync(path);
}));
// Then one big database operation
await _dataService.SaveBatchAsync(allRecords.SelectMany(r => r).ToList());
Getting Fancy: Smart Throttling Based on System Load
For serious production systems, here’s something cool, a file processor that watches system resources and adjusts itself:
public class AdaptiveFileProcessor
{
private SemaphoreSlim _semaphore;
private int _currentConcurrency;
private readonly int _minConcurrency = 4;
private readonly int _maxConcurrency = Environment.ProcessorCount * 4;
public AdaptiveFileProcessor()
{
_currentConcurrency = Environment.ProcessorCount * 2;
_semaphore = new SemaphoreSlim(_currentConcurrency);
}
public async Task ProcessFilesAsync(List<string> filePaths)
{
// Start a background task that watches system resources
var monitorTask = Task.Run(MonitorSystemResourcesAsync);
var tasks = new List<Task>();
foreach (var path in filePaths)
{
await _semaphore.WaitAsync();
tasks.Add(Task.Run(async () =>
{
try
{
await ProcessFileAsync(path);
}
finally
{
_semaphore.Release();
}
}));
}
await Task.WhenAll(tasks);
// In real code, you'd cancel the monitor when done
}
private async Task MonitorSystemResourcesAsync()
{
while (true)
{
await Task.Delay(5000); // Check every 5 seconds
// You'd use real performance counters here
double cpuUsage = GetCurrentCpuUsage();
double memoryPressure = GetMemoryPressure();
if (cpuUsage > 85 || memoryPressure > 85)
{
// System stressed? Slow down!
AdjustConcurrency(Math.Max(_currentConcurrency / 2, _minConcurrency));
}
else if (cpuUsage < 40 && memoryPressure < 50)
{
// System idle? Speed up!
AdjustConcurrency(Math.Min(_currentConcurrency + 2, _maxConcurrency));
}
}
}
private void AdjustConcurrency(int newConcurrency)
{
if (newConcurrency == _currentConcurrency) return;
if (newConcurrency > _currentConcurrency)
{
// We can add more slots easily
_semaphore.Release(newConcurrency - _currentConcurrency);
}
else
{
// But reducing is tricky - we make a new semaphore
var oldSemaphore = _semaphore;
_semaphore = new SemaphoreSlim(newConcurrency);
// Old semaphore gets cleaned up when all tasks release it
}
_currentConcurrency = newConcurrency;
Console.WriteLine($"Adjusted concurrency to {newConcurrency}");
}
// You'd implement these for real
private double GetCurrentCpuUsage() => 50;
private double GetMemoryPressure() => 50;
}
The adaptive system works by continuously monitoring resource usage and adjusting the concurrency:
┌─────────────────────────────────────────────────────────────────┐
│ Adaptive File Processor │
├─────────────┬─────────────────────────────────┬─────────────────┤
│ │ │ │
│ ┌───────────▼──────────┐ ┌───────────────▼─────────────┐ │
│ │ System Monitor │ │ File Processing │ │
│ │ │ │ │ │
│ │ ┌──────────────────┐ │ │ ┌─────────────┐ │ │
│ │ │ CPU Usage Check │ │ │ │ Task Queue │◀──┐ │ │
│ │ └──────────────────┘ │ │ └─────────────┘ │ │ │
│ │ ┌──────────────────┐ │ │ │ │ │
│ │ │ Memory Pressure │ │ │ ┌─────────────┐ │ │ │
│ │ └──────────────────┘ │ │ │ SemaphoreSlim│───┘ │ │
│ │ ┌──────────────────┐ │ │ └─────────────┘ │ │
│ │ │ I/O Throughput │ │ │ │ │
│ │ └──────────────────┘ │ │ │ │
│ └──────────┬───────────┘ └─────────────────────────────┘ │
│ │ │
│ ┌──────────▼───────────┐ │
│ │ Concurrency Adjuster │ │
│ │ │ │
│ │ ┌──────────────────┐ │ │
│ │ │ Increase/Decrease│ │ │
│ │ │ Active Threads │ │ │
│ │ └──────────────────┘ │ │
│ └──────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
Wrapping Up
When it comes to processing thousands of files in C#, going all-in with parallelism isn’t the answer, and neither is processing them one at a time. The sweet spot is controlled parallelism, doing enough at once to be fast, but not so many that you crash.
With tools like SemaphoreSlim, proper async file techniques, and smart batching, you can build systems that handle huge file loads without breaking a sweat.
Key Takeaways
Always throttle parallel operations - Use
SemaphoreSlimto limit concurrency based on your system’s capabilities.Use proper async I/O - Set
useAsync: truewhen creating file streams to truly benefit from asynchronous operations.Minimize memory usage - Process files line-by-line or in chunks rather than loading everything at once.
Batch database operations - Minimize database round-trips by saving records in batches.
Handle errors gracefully - Implement proper error handling so one bad file doesn’t crash your entire import.
Monitor and adapt - For production systems, implement real-time monitoring and consider adaptive throttling.
Choose the right approach for the job - Different file sizes and processing needs might call for different techniques:
- For small files: Simple
Task.WhenAllwith throttling - For medium files: Line-by-line processing with
IAsyncEnumerable - For huge files: Memory-mapped files or chunked processing
- For small files: Simple
Next time you need to import 5,000 CSVs, don’t worry, just remember to throttle your operations, use real async I/O, and be smart about resource usage. Your users (and your server) will thank you!
Further Reading
- Async Streams in .NET Core
- Memory-Mapped Files in .NET
- TPL Dataflow for Data Processing Pipelines
- System.IO.Pipelines for High-Performance IO