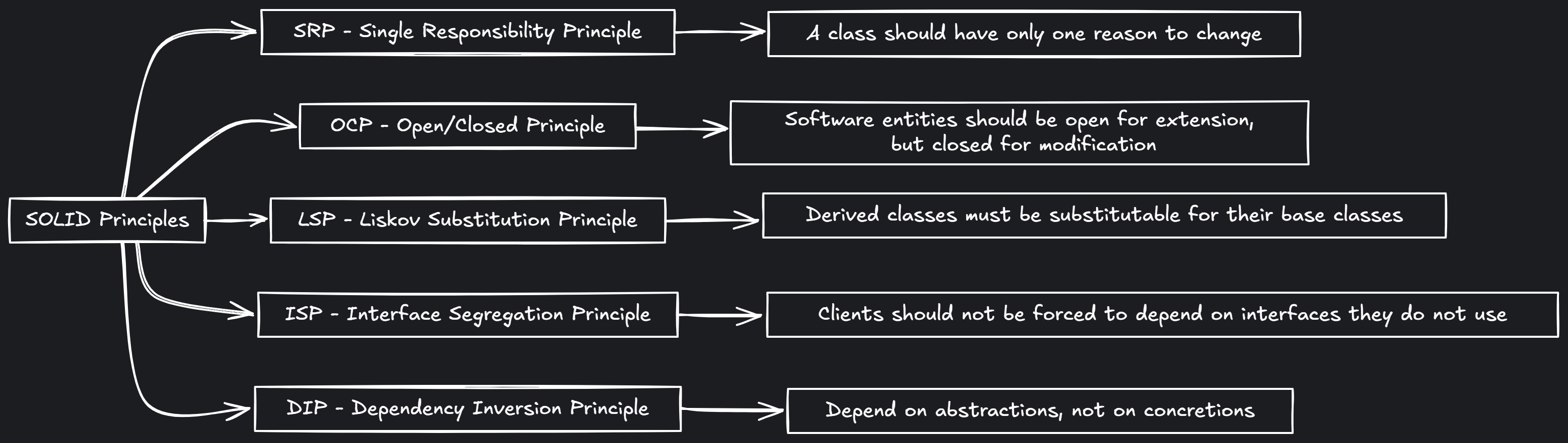
TL;DR - SOLID principles
- SRP: one class, one reason to change
- OCP: extend without modifying
- LSP: subclasses must behave like base types
- ISP: keep interfaces focused
- DIP: depend on abstractions, not implementations
Introduction
This SOLID tutorial in C# walks through each principle: SRP, OCP, LSP, ISP, and DIP, with practical code, refactoring examples, and real-world scenarios.
If you’ve been coding for a while, you’ve probably heard of SOLID. It’s a set of five design principles that Robert C. Martin (better known as “Uncle Bob”) came up with back in the early 2000s. Since then, these ideas have become pretty much essential knowledge for anyone writing object-oriented code.
But SOLID isn’t just another tech buzzword to memorize for interviews. These are practical ideas that actually help you write better code. I’ve found that following these principles helps me avoid creating those messy, brittle codebases that become a nightmare to change later on.
Let’s break down what these five principles are about:
Single Responsibility Principle (SRP): Keep it simple, a class should do just one thing. If you can’t describe what your class does without using “and,” it’s probably doing too much.
Open-Closed Principle (OCP): Write code that you can extend without having to modify the existing stuff. It’s like being able to add new features without breaking what already works.
Liskov Substitution Principle (LSP): If you replace an object with one of its subtypes, your program should still work correctly. No surprises or weird behavior.
Interface Segregation Principle (ISP): Keep interfaces focused and small rather than creating huge, kitchen-sink interfaces. Nobody likes being forced to implement methods they don’t need.
Dependency Inversion Principle (DIP): Depend on abstractions rather than concrete implementations. This makes your code much more flexible and testable.
When you put all these principles together, you get code that’s more flexible, easier to understand, and way less painful to change when requirements shift (which they always do).
Single Responsibility Principle
Single Responsibility Principle (SRP) Diagram: Class Responsibilities and Changes
flowchart TD
A[Class] -->|Should have| B[One Responsibility]
B -->|One reason| C[One Reason to Change]
A -.->|Avoid| D[Multiple Responsibilities]
D -.->|Leads to| E[Frequent Changes and Fragile Code]
This principle is probably the easiest to understand but surprisingly hard to follow in practice. We’ve all written those “god classes” that start simple but grow into monsters that do everything. This principle is closely related to the concept of high cohesion in object-oriented design.
When a class tries to handle too many things at once, you run into all sorts of problems:
- The code gets confusing and hard to follow
- Making changes becomes risky because you might break something unrelated
- Testing becomes a pain (or gets skipped entirely)
- You end up with classes that are too connected to other parts of your system
- New team members stare at your 1000-line class with horror
Following SRP gives you some real advantages:
- Your code becomes much easier to understand at a glance
- You can test each piece independently without complex setup
- When something changes, you only need to touch the specific class that handles that concern
- Your codebase becomes more modular
- Onboarding new developers goes more smoothly
SRP Violation Example
Here’s a classic example of code that breaks the SRP rule. This Employee class is trying to do way too much:
public class Employee
{
public string Name { get; set; }
public int Age { get; set; }
public string Address { get; set; }
public string Phone { get; set; }
public void Get()
{
// Code to get employee from database
Console.WriteLine($"Getting {Name} from database...");
}
public void Save()
{
// Code to save employee to database
Console.WriteLine($"Saving {Name} to database...");
}
public void Validate()
{
// Code to validate employee data
if (string.IsNullOrEmpty(Name) || Age < 18)
{
throw new ValidationException("Invalid employee data");
}
}
public void SendEmail()
{
// Code to send email to employee
Console.WriteLine($"Sending welcome email to {Name} at {Address}...");
}
}
You can spot the problem right away, this class is wearing too many hats. It’s trying to:
- Store employee data
- Handle database operations
- Validate data
- Send emails
Think about all the reasons this class might need to change: new database technology, updated validation rules, different email templates… it’s a maintenance nightmare waiting to happen!
SRP Compliant Solution
Let’s fix this by breaking up our monolithic class into smaller, focused ones:
// 1. Employee class -> just holds data
public class Employee
{
public string Name { get; set; }
public int Age { get; set; }
public string Address { get; set; }
public string Phone { get; set; }
}
// 2. Repository class -> just handles database stuff
public class EmployeeRepository
{
public Employee Get(int id)
{
// Code to get employee from database
Console.WriteLine("Getting employee from database...");
return new Employee();
}
public void Save(Employee employee)
{
// Code to save employee to database
Console.WriteLine($"Saving {employee.Name} to database...");
}
}
// 3. Validator class -> just handles checking if data is valid
public class EmployeeValidator
{
public bool Validate(Employee employee)
{
// Code to validate employee data
if (string.IsNullOrEmpty(employee.Name) || employee.Age < 18)
{
return false;
}
return true;
}
}
// 4. Email service class -> just handles sending emails
public class EmailService
{
public void SendWelcomeEmail(Employee employee)
{
// Code to send email to employee
Console.WriteLine($"Sending welcome email to {employee.Name}...");
}
}
Much better! Now each class does exactly one thing:
Employeejust stores dataEmployeeRepositoryhandles saving and loadingEmployeeValidatorchecks if the data is validEmailServicesends emails
Now when our requirements change, we know exactly which class to modify. Need to support a new database? Just update the repository. New validation rules? Just the validator needs to change. The code becomes so much easier to maintain!
Open-Closed Principle (OCP)
flowchart TD
A[Existing Class or Module] -->|Should be| B[Closed for Modification]
A -->|Should be| C[Open for Extension]
C -->|Add new behavior via| D[Inheritance / Interfaces / Composition]
B -.->|Avoid| E[Direct Changes to Existing Code]
E -.->|Prevents| F[Introducing Bugs in Stable Code]
Open-Closed Principle (OCP) Diagram: Extending Code Without Modifying Existing Functionality
The Open-Closed Principle (OCP) has a catchy phrase that sums it up: software should be open for extension but closed for modification. What does that actually mean? You should be able to add new features without changing existing code.
I think of OCP as the “don’t break what already works” principle. When you need to add new functionality, you extend the code rather than changing what’s already there and working fine.
Following this principle gives you some significant advantages:
- You avoid breaking existing, tested code when adding new features
- You reduce the risk of accidentally introducing bugs in code that was working fine
- Your system can grow while staying backward compatible
- You can test new functionality separately without retesting everything
- Your classes tend to stay more focused and better designed
How do you actually implement OCP in practice? There are a few common approaches:
- Use interfaces and abstract classes to create stable “contracts”
- Use inheritance and polymorphism to add new behavior
- Apply design patterns like Strategy, Template Method, or Decorator
- In languages that support them, extension methods can be handy
OCP Example
Here’s a real-world example that shows OCP in action, a shape calculator:
// 1. Create an interface that defines what a shape can do
public interface IShape
{
double CalculateArea();
}
// 2. Now we can create different shapes that implement this interface
public class Circle : IShape
{
public double Radius { get; set; }
public double CalculateArea()
{
return Math.PI * Radius * Radius;
}
}
public class Rectangle : IShape
{
public double Width { get; set; }
public double Height { get; set; }
public double CalculateArea()
{
return Width * Height;
}
}
public class Triangle : IShape
{
public double Base { get; set; }
public double Height { get; set; }
public double CalculateArea()
{
return (Base * Height) / 2;
}
}
// 3. Our calculator that works with any shape
public class ShapeCalculator
{
public double CalculateTotalArea(List<IShape> shapes)
{
double totalArea = 0;
foreach (var shape in shapes)
{
totalArea += shape.CalculateArea();
}
return totalArea;
}
}
// 4. Using our calculator with different shapes
public void Run()
{
var shapes = new List<IShape>
{
new Circle { Radius = 5 },
new Rectangle { Width = 4, Height = 6 },
new Triangle { Base = 3, Height = 8 }
};
var calculator = new ShapeCalculator();
double area = calculator.CalculateTotalArea(shapes);
Console.WriteLine($"Total area: {area}");
}
This approach is commonly used in web frameworks as well. For example, in ASP.NET Core routing, you can extend the routing system with custom constraints without modifying the core routing code.
Why This Works So Well
The beauty of this design is that our ShapeCalculator never needs to change, no matter how many new shapes we create. It’s “closed for modification.”
At the same time, we can easily add new shapes without touching any existing code. The system is “open for extension.”
For example, say we need to add support for pentagons. No problem! We just add a new class:
public class Pentagon : IShape
{
public double SideLength { get; set; }
public double Apothem { get; set; } // Distance from center to any side
public double CalculateArea()
{
return 5 * SideLength * Apothem / 2;
}
}
And we’re done! Our calculator works with pentagons immediately, with zero changes to the existing code. That’s OCP in action, and it’s incredibly powerful when your codebase starts to grow.
Liskov Substitution Principle
flowchart TD
A[Parent Class / Interface] -->|Defines| B[Expected Behavior]
C[Derived Class] -->|Inherits| A
C -->|Must Maintain| D[Same Expected Behavior]
E[Client Code] -->|Uses| A
E -->|Can Substitute| C
D -.->|If violated| F[Unexpected Behavior and Bugs]
Liskov Substitution Principle (LSP) Diagram: Subtypes Must Behave Like Base Types
The Liskov Substitution Principle (LSP) is named after Barbara Liskov, who introduced it in 1987. It states that you should be able to use any derived class in place of a parent class and have it behave in the same way without the code knowing the difference.
I think of LSP as the “no surprises” principle. If you’re expecting a Bird and I give you a Duck, everything should still work correctly.
In more practical terms, if your code works with a base class, it should work just as well with any class that inherits from it. When you violate this principle, you get unexpected behavior and weird bugs.
For LSP to work properly, subclasses need to:
- Accept the same input parameters (no new required parameters)
- Return values compatible with the base class
- Not throw new exceptions that the base class doesn’t throw
- Fulfill the same basic behaviors that clients expect
- Not change properties in ways that would surprise users of the base class
When LSP is broken, you’ll often see code that has:
- Type checking like
if (animal is Duck)orinstanceofchecks - Unexpected errors when using a subclass
- Different side effects than what you’d expect
- Special handling for certain subclasses that should “just work”
The Rectangle-Square Problem
The classic example used to explain LSP is the Rectangle-Square relationship. Here’s a good implementation that follows LSP:
// Base class with a common interface
public abstract class Shape
{
public abstract double CalculateArea();
}
// Rectangle implementation
public class Rectangle : Shape
{
public virtual double Width { get; set; }
public virtual double Height { get; set; }
public Rectangle(double width, double height)
{
Width = width;
Height = height;
}
public override double CalculateArea()
{
return Width * Height;
}
}
// Square implementation
public class Square : Shape
{
public double SideLength { get; set; }
public Square(double sideLength)
{
SideLength = sideLength;
}
public override double CalculateArea()
{
return SideLength * SideLength;
}
}
// Client code that works with shapes
public void ProcessShapes()
{
List<Shape> shapes = new List<Shape>
{
new Rectangle(10, 5),
new Square(8)
};
double totalArea = 0;
foreach (var shape in shapes)
{
totalArea += shape.CalculateArea();
}
Console.WriteLine($"Total area: {totalArea}"); // Works fine: 114
}
This works great because both Rectangle and Square are just different kinds of Shape. The code that uses Shape doesn’t care about the specific type.
Where Things Go Wrong
Now here’s where many developers make a mistake. Since in mathematics a square is technically a special kind of rectangle (where width equals height), they try to model it that way in code:
public class Rectangle
{
public virtual double Width { get; set; }
public virtual double Height { get; set; }
public Rectangle(double width, double height)
{
Width = width;
Height = height;
}
public double CalculateArea()
{
return Width * Height;
}
}
// This seems logical but causes problems
public class Square : Rectangle
{
public Square(double side) : base(side, side) { }
// We need to override these to keep the square's properties
public override double Width
{
get { return base.Width; }
set
{
base.Width = value;
base.Height = value; // Must keep sides equal
}
}
public override double Height
{
get { return base.Height; }
set
{
base.Width = value; // Must keep sides equal
base.Height = value;
}
}
}
The problem shows up when someone tries to use a Square as if it were a Rectangle:
public void ResizeRectangle(Rectangle rectangle)
{
rectangle.Width = 10;
rectangle.Height = 5;
// For a normal Rectangle: Area = 10 * 5 = 50
// For a Square: Area = 5 * 5 = 25 (surprise!)
Console.WriteLine($"Expected area: 50, Actual area: {rectangle.CalculateArea()}");
}
If you pass a Square to this method, you get unexpected behavior. When you set the width to 10, it works, but then when you set the height to 5, both height AND width become 5 (to keep it a square). So the area is 25, not 50 as expected. That’s an LSP violation, the subclass can’t be used in place of the base class without surprising behavior.
Interface Segregation Principle
flowchart TD
A[Fat Interface] -->|Forces| B[Classes to implement unused methods]
B -.->|Causes| C[Unnecessary Complexity and Fragile Code]
D[Split into Small Interfaces] -->|Each defines| E[Focused Responsibilities]
F[Classes] -->|Implement only needed interfaces| E
E -.->|Results in| G[Cleaner, Maintainable Code]
Interface Segregation Principle (ISP) Diagram: Avoiding Fat Interfaces
The Interface Segregation Principle (ISP) says that you shouldn’t force classes to implement interfaces they don’t use. It’s better to have several small interfaces than one big catch-all interface.
I like to think of this as the “don’t pay for what you don’t use” principle. Why implement methods your class doesn’t need?
This principle came about because of “fat interfaces”, interfaces with too many methods that force implementing classes to provide functionality they don’t care about. When you create smaller, more focused interfaces, classes can pick just the ones they need.
Following ISP gives you several benefits:
- Your code becomes less coupled because clients only depend on what they actually use
- Your interfaces are more focused and easier to understand
- Changes to one interface don’t break unrelated code
- Testing is simpler because you can mock smaller interfaces
- Your code becomes more flexible and adaptable
These benefits are particularly noticeable in languages with strong interface support like C# and TypeScript.
Here are some warning signs that you might be violating ISP:
- You have empty method implementations that just return null or do nothing
- You have methods that throw NotImplementedException
- Classes only use a small fraction of the methods from an interface they implement
- Your interfaces change frequently for reasons that don’t affect most implementers
The Printer Problem
Let’s look at a common example of an ISP violation, trying to make a single printer interface that handles everything:
// This interface is trying to do too much
public interface IMultiFunctionDevice
{
void Print(Document document);
void Scan(Document document);
void Fax(Document document);
void Copy(Document document);
void PrintDuplex(Document document);
void ScanColor(Document document);
}
// A basic printer that can't do most of these things
public class EconomyPrinter : IMultiFunctionDevice
{
public void Print(Document document)
{
Console.WriteLine("Printing document...");
}
// Now we're stuck implementing methods we don't support
public void Scan(Document document)
{
throw new NotSupportedException("This printer can't scan");
}
public void Fax(Document document)
{
throw new NotSupportedException("This printer can't fax");
}
public void Copy(Document document)
{
throw new NotSupportedException("This printer can't copy");
}
public void PrintDuplex(Document document)
{
throw new NotSupportedException("This printer can't print double-sided");
}
public void ScanColor(Document document)
{
throw new NotSupportedException("This printer can't scan in color");
}
}
This is a mess! Our poor EconomyPrinter has to implement a bunch of methods it can’t actually support, and anyone trying to use those methods gets exceptions at runtime. Not good.
A Better Way: Smaller, Focused Interfaces
Here’s how we could fix this with ISP:
// Simple document class
public class Document
{
public string Content { get; set; }
public string Name { get; set; }
}
// Break down the big interface into smaller ones
public interface IPrinter
{
void Print(Document document);
}
public interface IScanner
{
void Scan(Document document);
}
public interface IFax
{
void Fax(Document document);
}
public interface ICopier
{
void Copy(Document document);
}
public interface IDuplexPrinter
{
void PrintDuplex(Document document);
}
// Now our basic printer only implements what it can actually do
public class EconomyPrinter : IPrinter
{
public void Print(Document document)
{
Console.WriteLine($"Printing: {document.Name}");
}
}
// The fancy printer can implement multiple interfaces
public class SuperPrinter : IPrinter, IScanner, IFax, ICopier, IDuplexPrinter
{
public void Print(Document document)
{
Console.WriteLine($"Printing: {document.Name}");
}
public void Scan(Document document)
{
Console.WriteLine($"Scanning: {document.Name}");
}
public void Fax(Document document)
{
Console.WriteLine($"Faxing: {document.Name}");
}
public void Copy(Document document)
{
Console.WriteLine($"Copying: {document.Name}");
}
public void PrintDuplex(Document document)
{
Console.WriteLine($"Printing double-sided: {document.Name}");
}
}
Much better! Now if you only need to print things, your client code can just depend on IPrinter:
public class PrintingService
{
private readonly IPrinter _printer;
public PrintingService(IPrinter printer)
{
_printer = printer;
}
public void Print(Document document)
{
_printer.Print(document);
}
}
This works with any printer, basic or advanced, because they all properly implement IPrinter. No more surprises or unnecessary dependencies!
Dependency Inversion Principle
flowchart TD
A[High-Level Module] -- depends on --> C[Abstraction -Interface]
B[Low-Level Module] -- implements --> C
A -. avoids .-> B[Low-Level Module]
B -. depends on .-> C
C -.->|Abstractions are stable<br>Details can change| D[Flexible, Maintainable Design]
Dependency Inversion Principle (DIP) Diagram: Depend on Abstractions, Not Implementations
The Dependency Inversion Principle (DIP). flips the traditional way of thinking about dependencies:
- High-level modules shouldn’t depend on low-level modules. Both should depend on abstractions.
- Abstractions shouldn’t depend on details. Details should depend on abstractions.
I think of this as the “depend on concepts, not specifics” principle. Instead of having your business logic directly tied to database code or UI frameworks, everything depends on interfaces that define what you need rather than how it’s done.
People often mix up DIP with Dependency Injection (DI), but they’re different:
- DIP is the principle (what you should do): rely on abstractions, not specific implementations
- DI is a technique (how you do it): a way to provide dependencies from outside a class
Following DIP gives you some major benefits:
- Your code becomes loosely coupled, so changes in one area don’t break others
- You can easily test your code by swapping real components with test doubles
- You can switch implementations without changing your core business logic
- Your important business rules stay stable, even when external tools change
- Your code becomes more portable between different platforms or frameworks
DIP in Action: User Management System
Here’s a real-world example of how DIP works in a user management system:
// 1. First, we define an interface that both layers will depend on
public interface IUserRepository
{
User GetById(int userId);
void Save(User user);
void Delete(int userId);
}
// 2. Our business logic depends on the interface, not a specific implementation
public class UserService
{
private readonly IUserRepository _userRepository;
// We get the repository from outside (this is Dependency Injection)
public UserService(IUserRepository userRepository)
{
_userRepository = userRepository;
}
public void RegisterUser(string username, string email)
{
// Business rules
if (string.IsNullOrEmpty(username) || string.IsNullOrEmpty(email))
throw new ArgumentException("You need both a username and email");
// We work with the abstraction, not caring about the actual implementation
var user = new User { Username = username, Email = email };
_userRepository.Save(user);
}
public User GetUser(int userId)
{
return _userRepository.GetById(userId);
}
}
// 3. Here's one specific implementation -> SQL Server
public class SqlUserRepository : IUserRepository
{
private readonly string _connectionString;
public SqlUserRepository(string connectionString)
{
_connectionString = connectionString;
}
public User GetById(int userId)
{
// SQL-specific code here
Console.WriteLine($"Getting user {userId} from SQL database");
return new User { Id = userId, Username = "johndoe" };
}
public void Save(User user)
{
// SQL-specific code here
Console.WriteLine($"Saving {user.Username} to SQL database");
}
public void Delete(int userId)
{
// SQL-specific code here
Console.WriteLine($"Deleting user {userId} from SQL database");
}
}
// 4. We could also have a MongoDB implementation
public class MongoUserRepository : IUserRepository
{
private readonly string _connectionString;
public MongoUserRepository(string connectionString)
{
_connectionString = connectionString;
}
public User GetById(int userId)
{
Console.WriteLine($"Getting user {userId} from MongoDB");
return new User { Id = userId, Username = "johndoe" };
}
public void Save(User user)
{
Console.WriteLine($"Saving {user.Username} to MongoDB");
}
public void Delete(int userId)
{
Console.WriteLine($"Deleting user {userId} from MongoDB");
}
}
// 5. Our application wires everything up
public class Application
{
public static void Main()
{
// Here we decide which implementation to use
var connectionString = "Server=myServer;Database=myDB;User=myUser;Password=myPassword;";
IUserRepository repository = new SqlUserRepository(connectionString);
UserService userService = new UserService(repository);
// Use the service
userService.RegisterUser("johndoe", "john@example.com");
// If we want to switch to MongoDB, it's just one line change:
// IUserRepository repository = new MongoUserRepository("mongodb://localhost:27017");
}
}
What makes this a good example of DIP?
- Our UserService (the important business logic) doesn’t know or care what kind of database we’re using
- Both the high-level module (UserService) and low-level modules (repositories) depend on the IUserRepository interface
- We can completely swap out database technologies without touching our business logic
- Testing becomes really easy, we can create a fake repository for testing
Conclusion: Using SOLID in Your Code
SOLID principles aren’t just theoretical concepts, they’re practical tools that can dramatically improve your code. Here’s a quick recap of what we’ve covered:
Single Responsibility Principle: Each class should do just one thing. When a class has too many responsibilities, break it up into smaller, focused classes.
Open-Closed Principle: Write code that you can extend without modifying. Use abstractions and polymorphism so you can add new functionality without touching existing code.
Liskov Substitution Principle: Subclasses should work anywhere their parent classes do. Don’t surprise users with unexpected behavior in derived classes.
Interface Segregation Principle: Create small, specific interfaces rather than large, general-purpose ones. Don’t force classes to implement methods they don’t need.
Dependency Inversion Principle: Depend on abstractions, not concrete implementations. This keeps your code flexible and testable.
These principles work together to help you build better software. When you follow them, you’ll notice:
- Your code becomes easier to understand and change
- You can test each component in isolation
- Your system adapts better to new requirements
- You can reuse components in ways you didn’t expect originally
Keep in mind that SOLID principles are guidelines, not rigid rules. Use your judgment about when and how to apply them. Sometimes a small violation makes sense for simplicity or performance reasons, and that’s okay.
If you’re new to these ideas, don’t worry about getting everything perfect right away. Start by focusing on the problems each principle helps solve, not just memorizing the definitions. Look for chances to refactor existing code using these principles, and over time, you’ll develop a feel for when to apply them.
If you want to dive deeper into these concepts, I recommend checking out the my series of SOLID principles in C#.
Related Articles
To deepen your understanding of object-oriented design and SOLID principles, check out these related articles:
- Object-Oriented Programming: Core Principles and C# Implementation - Master the four pillars of OOP
- Cohesion vs Coupling in Object-Oriented Programming - Learn how these concepts impact code quality
- Understanding Abstract Classes in C# - Explore a key mechanism for inheritance
- Abstract Class vs Interface in C# - Compare two important abstraction approaches
- Dependency Inversion vs Dependency Injection vs IoC - Understand these related but distinct concepts
- Static Classes vs Singleton Pattern in C# - Compare approaches for global access
Frequently Asked Questions
What does SOLID stand for in programming?
Why are SOLID principles important for developers?
How does the Single Responsibility Principle improve code?
What’s a good example of the Open-Closed Principle?
How do I know if I’m violating the Liskov Substitution Principle?
What problems does Interface Segregation solve?
How is Dependency Inversion different from Dependency Injection?
What’s the easiest SOLID principle to start applying in my code?
Can SOLID principles be overused or misapplied?
Related Posts
- The Rectangle-Square Problem: What It Teaches Us About Liskov Substitution Principle (LSP)
- How to Apply the Open/Closed Principle Without Turning Every Feature Into a Plugin
- Single Resposibility Principle - What's a "Single Reason to Change" and Why It Matters?
- How Does Composition Support the SOLID Principles? (C# Examples & Best Practices)
- How Polymorphism Makes C# Code Flexible: Real-World Examples and Best Practices