TL;DR
- Slow SQL JOINs are usually caused by missing or poorly designed indexes.
- Use composite indexes: put filter columns first, JOIN columns second.
- Analyze execution plans to spot scans and inefficient joins.
- Avoid functions and type mismatches in WHERE clauses to enable index usage.
- Regularly monitor index usage and adjust as data and queries evolve.
- The right indexes can turn a 30-second JOIN query into a sub-second result.
- Always test and review execution plans after index changes for best performance.
When you’re dealing with a database that’s grown beyond a few thousand rows, JOIN operations can quickly become your biggest performance bottleneck. I’ve seen too many queries that worked fine in development crawl to a halt in production, leaving developers scratching their heads while users complain about slow page loads.
The culprit is usually the same: poorly indexed JOIN conditions that force the database to scan entire tables instead of efficiently locating the rows it needs. Today, I’ll walk you through a real scenario I encountered recently and show you exactly how to diagnose and fix these performance issues using strategic indexing.
The Problem: A Slow E-commerce Query
Let’s start with a typical e-commerce scenario. You have customers placing orders for products, and you need to generate a report showing order details with customer information and product data. Here’s the query that was causing problems:
-- Original slow query
SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= '2024-01-01'
AND p.category = 'Electronics'
AND c.region = 'North America'
ORDER BY o.order_date DESC;
This query joins four tables and applies filters on three different columns. In a database with 10,000 customers, 50,000 orders, and 150,000 order items, this query was taking over 30 seconds to complete.
Setting Up the Test Environment
To demonstrate these optimization techniques, I’ve created a realistic test dataset that mirrors the performance characteristics of larger production systems. Here’s the complete setup script that creates our tables and populates them with representative data:
-- Drop existing tables if they exist
IF OBJECT_ID('ORDER_ITEMS') IS NOT NULL DROP TABLE ORDER_ITEMS;
IF OBJECT_ID('ORDERS') IS NOT NULL DROP TABLE ORDERS;
IF OBJECT_ID('PRODUCTS') IS NOT NULL DROP TABLE PRODUCTS;
IF OBJECT_ID('CUSTOMERS') IS NOT NULL DROP TABLE CUSTOMERS;
-- Step 1: Create tables
CREATE TABLE CUSTOMERS (
customer_id INT IDENTITY(1,1) PRIMARY KEY,
customer_name VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE,
region VARCHAR(50)
);
CREATE TABLE PRODUCTS (
product_id INT IDENTITY(1,1) PRIMARY KEY,
product_name VARCHAR(100) NOT NULL,
category VARCHAR(50)
);
CREATE TABLE ORDERS (
order_id INT IDENTITY(1,1) PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
FOREIGN KEY (customer_id) REFERENCES CUSTOMERS(customer_id) ON DELETE CASCADE
);
CREATE TABLE ORDER_ITEMS (
order_item_id INT IDENTITY(1,1) PRIMARY KEY,
order_id INT NOT NULL,
product_id INT NOT NULL,
quantity INT NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
FOREIGN KEY (order_id) REFERENCES ORDERS(order_id) ON DELETE CASCADE,
FOREIGN KEY (product_id) REFERENCES PRODUCTS(product_id) ON DELETE CASCADE
);
-- Step 2: Create helper lookup tables
CREATE TABLE #Names (val VARCHAR(50));
INSERT INTO #Names VALUES ('John'), ('Alice'), ('Raj'), ('Emma'), ('Liu'), ('Carlos'), ('Sara'), ('Max');
CREATE TABLE #Regions (val VARCHAR(50));
INSERT INTO #Regions VALUES ('North'), ('South'), ('East'), ('West');
CREATE TABLE #Categories (val VARCHAR(50));
INSERT INTO #Categories VALUES ('Electronics'), ('Clothing'), ('Books'), ('Home'), ('Toys');
-- Step 3: Insert customers
DECLARE @i INT = 1;
WHILE @i <= 10000
BEGIN
DECLARE @Name VARCHAR(50) = (SELECT TOP 1 val FROM #Names ORDER BY NEWID());
DECLARE @Region VARCHAR(50) = (SELECT TOP 1 val FROM #Regions ORDER BY NEWID());
INSERT INTO CUSTOMERS (customer_name, email, region)
VALUES (
@Name + ' ' + CAST(@i AS VARCHAR),
LOWER(@Name + CAST(@i AS VARCHAR) + '@example.com'),
@Region
);
SET @i += 1;
END
-- Step 4: Insert products
SET @i = 1;
WHILE @i <= 2000
BEGIN
DECLARE @Category VARCHAR(50) = (SELECT TOP 1 val FROM #Categories ORDER BY NEWID());
INSERT INTO PRODUCTS (product_name, category)
VALUES (
'Product ' + CAST(@i AS VARCHAR),
@Category
);
SET @i += 1;
END
-- Step 5: Insert orders
SET @i = 1;
WHILE @i <= 50000
BEGIN
INSERT INTO ORDERS (customer_id, order_date, total_amount)
VALUES (
ABS(CHECKSUM(NEWID()) % 1000) + 1,
DATEADD(DAY, -ABS(CHECKSUM(NEWID()) % 365), GETDATE()),
ROUND(RAND() * 1000 + 50, 2)
);
SET @i += 1;
END
-- Step 6: Insert order items
SET @i = 1;
WHILE @i <= 150000
BEGIN
INSERT ORDER_ITEMS (order_id, product_id, quantity, unit_price)
VALUES (
ABS(CHECKSUM(NEWID()) % 5000) + 1,
ABS(CHECKSUM(NEWID()) % 200) + 1,
ABS(CHECKSUM(NEWID()) % 5) + 1,
ROUND(RAND() * 100 + 10, 2)
);
SET @i += 1;
END
-- Step 7: Clean up temp tables
DROP TABLE #Names;
DROP TABLE #Regions;
DROP TABLE #Categories;
-- Step 8: Show row counts
SELECT 'CUSTOMERS' AS TableName, COUNT(*) AS Rows FROM CUSTOMERS
UNION ALL
SELECT 'PRODUCTS', COUNT(*) FROM PRODUCTS
UNION ALL
SELECT 'ORDERS', COUNT(*) FROM ORDERS
UNION ALL
SELECT 'ORDER_ITEMS', COUNT(*) FROM ORDER_ITEMS;
This script creates a close realistic e-commerce dataset with:
- 10,000 customers
- 2,000 products in 5 different categories
- 50,000 orders spanning the last year
- 150,000 order items with realistic quantity and pricing data
The data distribution mimics real-world scenarios where some customers place multiple orders, products vary in popularity, and order dates are spread across time periods.
This setup allows us to demonstrate meaningful performance improvements that translate to production environments.
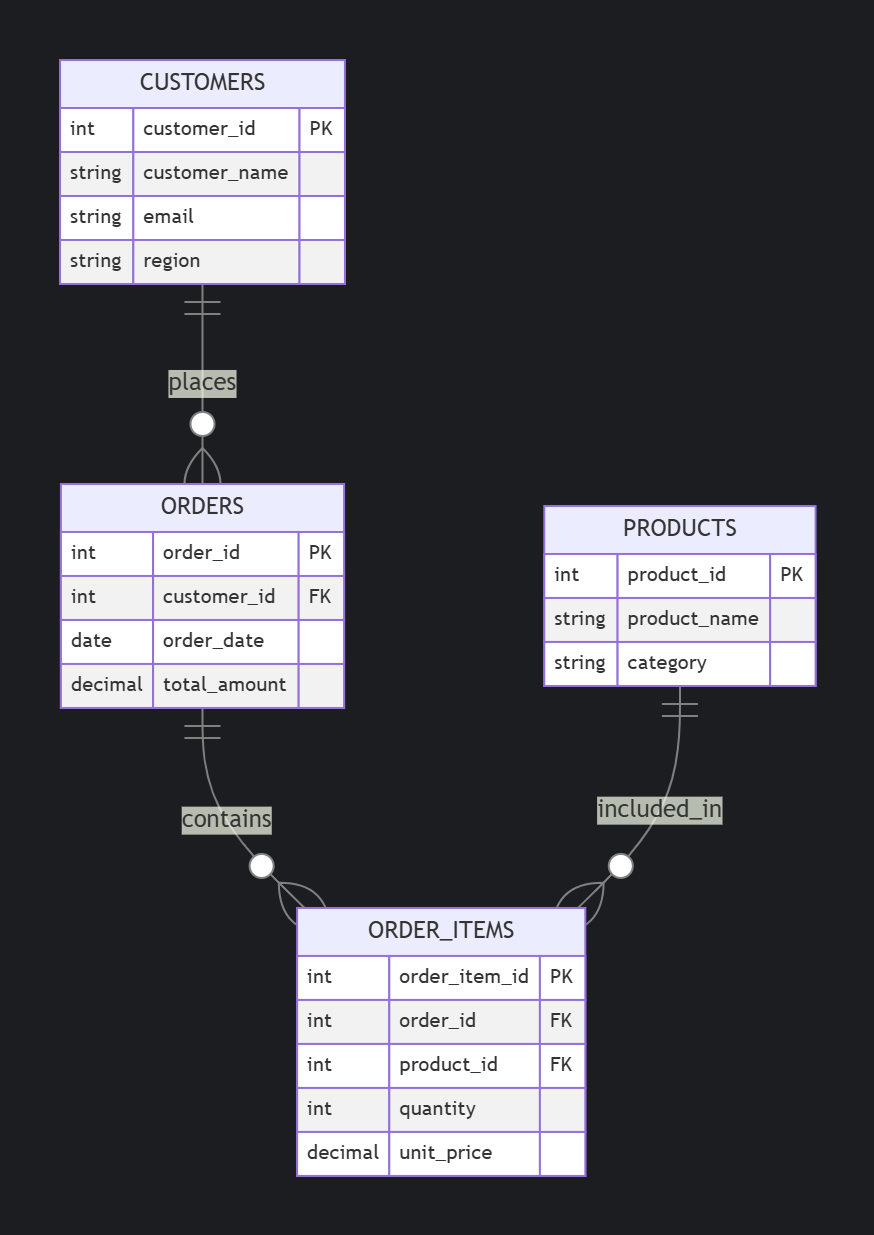
Optimizing JOIN-Heavy SQL Queries: How Composite Indexes Transform Query Performance
Understanding the Performance Problem
Now let’s run our problematic query against this dataset to see the performance issues firsthand. Note that I’ve switched to SQL Server syntax to match our test environment:
-- Original slow query (SQL Server syntax)
SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= '2024-01-01'
AND p.category = 'Electronics'
AND c.region = 'North'
ORDER BY o.order_date DESC;
Before jumping into solutions, let’s see what the database was actually doing. In SQL Server, we can use SET STATISTICS IO ON and examine the execution plan:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
-- Run the query and observe the execution plan
SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= '2024-01-01'
AND p.category = 'Electronics'
AND c.region = 'North'
ORDER BY o.order_date DESC;
Query Statistics
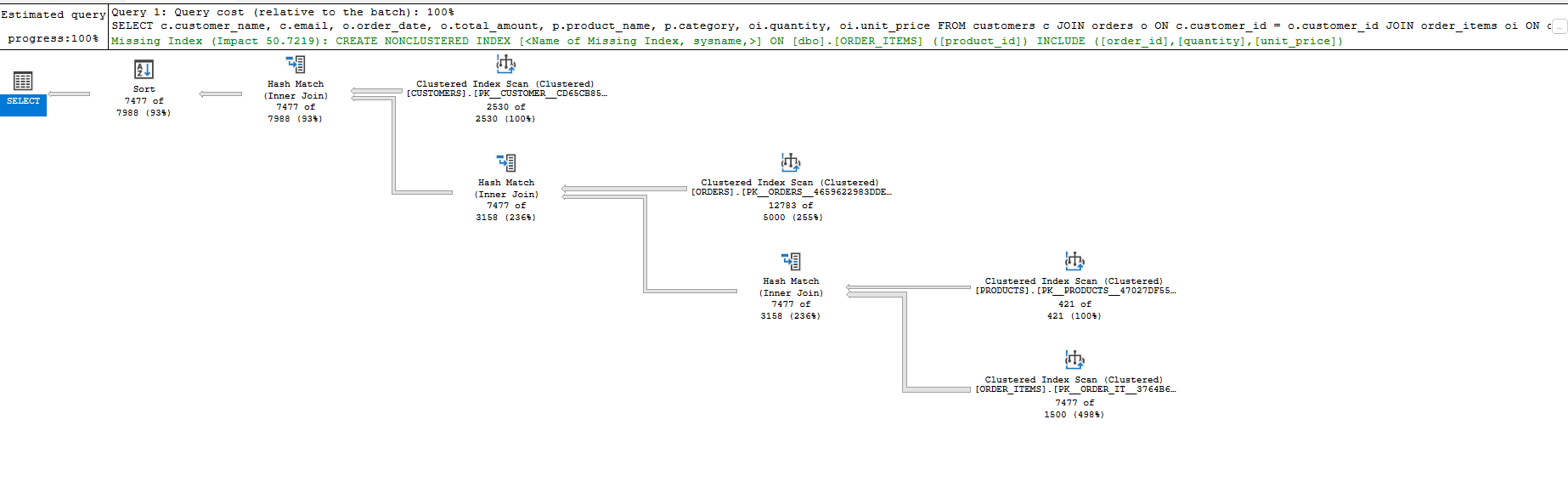
Query Statistics Before Index Optimization: Table Scans and Hash Joins Slow Down JOIN-Heavy Queries
Rows Executes StmtText StmtId NodeId Parent PhysicalOp LogicalOp Argument DefinedValues EstimateRows EstimateIO EstimateCPU AvgRowSize TotalSubtreeCost OutputList Warnings Type Parallel EstimateExecutions
-------------------- -------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ----------- ----------- ----------- ------------------------------ ------------------------------ ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------------------------------------ ------------- ------------- ------------- ----------- ---------------- ----------------------------------------------------------------------------------------------------------------------------------------------- -------- ---------------------------------------------------------------- -------- ------------------
7477 1 SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order 1 1 0 NULL NULL NULL NULL 7988.475 NULL NULL NULL 1.285269 NULL NULL SELECT 0 NULL
7477 1 |--Sort(ORDER BY:([o].[order_date] DESC)) 1 2 1 Sort Sort ORDER BY:([o].[order_date] DESC) NULL 7988.475 0.003753754 0.1726016 198 1.285269 [c].[customer_name], [c].[email], [o].[order_date], [o].[total_amount], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
7477 1 |--Hash Match(Inner Join, HASH:([c].[customer_id])=([o].[customer_id])DEFINE:([Opt_Bitmap1011])) 1 3 2 Hash Match Inner Join HASH:([c].[customer_id])=([o].[customer_id]) [Opt_Bitmap1011] 7988.475 0 0.09374703 198 1.108914 [c].[customer_name], [c].[email], [o].[order_date], [o].[total_amount], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
2530 1 |--Clustered Index Scan(OBJECT:([order_db].[dbo].[CUSTOMERS].[PK__CUSTOMER__CD65CB850D7021DC] AS [c]), WHERE:([order_db].[dbo].[CUSTOMERS].[region] as [c].[region]='North')) 1 4 3 Clustered Index Scan Clustered Index Scan OBJECT:([order_db].[dbo].[CUSTOMERS].[PK__CUSTOMER__CD65CB850D7021DC] AS [c]), WHERE:([order_db].[dbo].[CUSTOMERS].[region] as [c].[region]='North') [c].[customer_id], [c].[customer_name], [c].[email] 2530 0.05275463 0.011157 123 0.06391163 [c].[customer_id], [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
7477 1 |--Hash Match(Inner Join, HASH:([o].[order_id])=([oi].[order_id])DEFINE:([Opt_Bitmap1012])) 1 5 3 Hash Match Inner Join HASH:([o].[order_id])=([oi].[order_id]) [Opt_Bitmap1012] 3157.5 0 0.0604821 98 0.9464521 [o].[customer_id], [o].[order_date], [o].[total_amount], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
12783 1 |--Clustered Index Scan(OBJECT:([order_db].[dbo].[ORDERS].[PK__ORDERS__4659622983DDEAE4] AS [o]), WHERE:([order_db].[dbo].[ORDERS].[order_date] as [o].[order_date]>='2024-01-01' AND PROBE([Opt_Bitmap1011],[order_db].[dbo].[ORDERS].[custom 1 7 5 Clustered Index Scan Clustered Index Scan OBJECT:([order_db].[dbo].[ORDERS].[PK__ORDERS__4659622983DDEAE4] AS [o]), WHERE:([order_db].[dbo].[ORDERS].[order_date] as [o].[order_date]>='2024-01-01' AND PROBE([Opt_Bitmap1011],[order_db].[dbo].[ORDERS].[customer_id] as [o].[customer_id])) [o].[order_id], [o].[customer_id], [o].[order_date], [o].[total_amount] 5000 0.1357176 0.055107 27 0.1908246 [o].[order_id], [o].[customer_id], [o].[order_date], [o].[total_amount] NULL PLAN_ROW 0 1
7477 1 |--Hash Match(Inner Join, HASH:([p].[product_id])=([oi].[product_id])DEFINE:([Opt_Bitmap1013])) 1 8 5 Hash Match Inner Join HASH:([p].[product_id])=([oi].[product_id]) [Opt_Bitmap1013] 3157.5 0 0.02323204 86 0.6711424 [oi].[order_id], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
421 1 |--Clustered Index Scan(OBJECT:([order_db].[dbo].[PRODUCTS].[PK__PRODUCTS__47027DF555FB1A3C] AS [p]), WHERE:([order_db].[dbo].[PRODUCTS].[category] as [p].[category]='Electronics')) 1 9 8 Clustered Index Scan Clustered Index Scan OBJECT:([order_db].[dbo].[PRODUCTS].[PK__PRODUCTS__47027DF555FB1A3C] AS [p]), WHERE:([order_db].[dbo].[PRODUCTS].[category] as [p].[category]='Electronics') [p].[product_id], [p].[product_name], [p].[category] 421 0.009791667 0.002357 73 0.01214867 [p].[product_id], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
7477 1 |--Clustered Index Scan(OBJECT:([order_db].[dbo].[ORDER_ITEMS].[PK__ORDER_IT__3764B6BC97A52615] AS [oi]), WHERE:(PROBE([Opt_Bitmap1012],[order_db].[dbo].[ORDER_ITEMS].[order_id] as [oi].[order_id]) AND PROBE([Opt_Bitmap1013],[order_d 1 11 8 Clustered Index Scan Clustered Index Scan OBJECT:([order_db].[dbo].[ORDER_ITEMS].[PK__ORDER_IT__3764B6BC97A52615] AS [oi]), WHERE:(PROBE([Opt_Bitmap1012],[order_db].[dbo].[ORDER_ITEMS].[order_id] as [oi].[order_id]) AND PROBE([Opt_Bitmap1013],[order_db].[dbo].[ORDER_ITEMS].[product_id] as [oi].[p [oi].[order_id], [oi].[product_id], [oi].[quantity], [oi].[unit_price] 1500 0.4697917 0.165007 28 0.6347986 [oi].[order_id], [oi].[product_id], [oi].[quantity], [oi].[unit_price] NULL PLAN_ROW 0 1
(9 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 366 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Completion time: 2025-06-26T17:04:05.0760455
Execution Results
- Rows returned: 7,477
- Elapsed time: 366 ms
- CPU time: 31 ms
- Joins: All performed using Hash Match
- Scans: All tables used Clustered Index Scans
- Sort: Final sort on order_date DESC adds overhead
The query worked but was not index-backed. Every filter and join triggered full scans and in-memory joins. As data grows, this design won’t scale.
Execution plan
Execution Plan Before Index Optimization: Table Scans and Hash Joins Slow Down JOIN-Heavy Queries
The execution plan reveals several red flags typical of unoptimized queries:
- Table Scan operations on multiple tables instead of efficient index seeks
- Hash Join operations that require building hash tables in memory
- Sort operations to handle the ORDER BY clause
- High logical reads indicating excessive data page access
Without proper indexes, the database engine has no choice but to scan entire tables to find the rows that match our filter conditions. Each JOIN becomes a costly operation that examines far more data than necessary.
To understand the impact of index scan vs index seek operations, you can refer to this Index Seek vs Index Scan post.
Index Fundamentals for JOIN Operations
Before we fix this query, let’s quickly review how indexes help with JOINs. Think of an index as a sorted lookup table that points to the actual data rows. When you JOIN tables, the database can use these indexes to quickly find matching rows instead of scanning everything.
There are two main types of indexes to consider:
Clustered indexes physically order the table data and typically exist on primary keys. Each table can have only one clustered index because the data can only be physically sorted one way.
Non-clustered indexes are separate structures that point back to the actual data rows. You can have multiple non-clustered indexes on a table, and they’re perfect for supporting JOIN conditions and WHERE clauses.
For JOIN-heavy queries, the key is creating indexes that support both the JOIN conditions and the filter conditions in your WHERE clause.
Building Composite Indexes for Multi-Column Filtering
The magic happens when you create composite indexes that cover multiple columns used together in your queries. The order of columns in a composite index matters tremendously for performance.
Here’s the indexing strategy I implemented for our problematic query:
-- Index for customers table (region filter + JOIN column)
CREATE INDEX idx_customers_region_id ON customers (region, customer_id);
-- Index for orders table (date filter + foreign key + primary key for covering)
CREATE INDEX idx_orders_date_customer ON orders (order_date, customer_id, order_id);
-- Index for order_items table (JOIN columns)
CREATE INDEX idx_order_items_order_product ON order_items (order_id, product_id);
-- Index for products table (category filter + JOIN column)
CREATE INDEX idx_products_category_id ON products (category, product_id);
-- Covering index for order_items to speed up queries that select these columns
CREATE NONCLUSTERED INDEX idx_order_items_product_id_order_id_quantity_unit_price ON order_items(product_id) INCLUDE(order_id, quantity, unit_price)
-- Covering index for orders to optimize queries that select these columns
CREATE NONCLUSTERED INDEX idx_Orders_order_date_customer_id_total_amount ON Orders(order_date) INCLUDE(customer_id, total_amount)
The column order follows a simple rule: filter columns first, JOIN columns second. This allows the database to quickly narrow down the result set using the filter conditions, then efficiently perform the JOIN operations on the smaller dataset.
Let’s break down why each index works:
idx_customers_region_id: Filters by region first, then provides quick access to customer_id for JOINsidx_orders_date_customer: Uses the date range filter to eliminate old orders, then supports JOINs with customers and order_itemsidx_products_category_id: Filters products by category, then supports JOINs with order_itemsidx_order_items_product_id_order_id_quantity_unit_price: Creates a covering index onorder_itemsfor queries that filter or join byproduct_idand need to quickly retrieveorder_id,quantity, andunit_pricewithout extra lookups. This index speeds up JOINs with products and supports fast data retrieval for reporting.idx_Orders_order_date_customer_id_total_amount: Provides a covering index on orders for queries filtering byorder_dateand needingcustomer_idandtotal_amount. This index allows efficient index seeks for date range filters and supports JOINs with customers and order_items, reducing the need for full table scans.
To know more about the importance of covering indexes, you can refer to this Speed Up Your SQL Queries with Covering Indexes .
Reading the Optimized Execution Plan
After creating these indexes, let’s test the same query again to measure the improvement:
-- Create the indexes first
CREATE INDEX idx_customers_region_id ON customers (region, customer_id);
CREATE INDEX idx_orders_date_customer ON orders (order_date, customer_id, order_id);
CREATE INDEX idx_order_items_order_product ON order_items (order_id, product_id);
CREATE INDEX idx_products_category_id ON products (category, product_id);
CREATE NONCLUSTERED INDEX idx_order_items_product_id_order_id_quantity_unit_price ON order_items(product_id) INCLUDE(order_id, quantity, unit_price)
CREATE NONCLUSTERED INDEX idx_Orders_order_date_customer_id_total_amount ON Orders(order_date) INCLUDE(customer_id, total_amount)
-- Now run the same query with statistics enabled
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= '2024-01-01'
AND p.category = 'Electronics'
AND c.region = 'North'
ORDER BY o.order_date DESC;
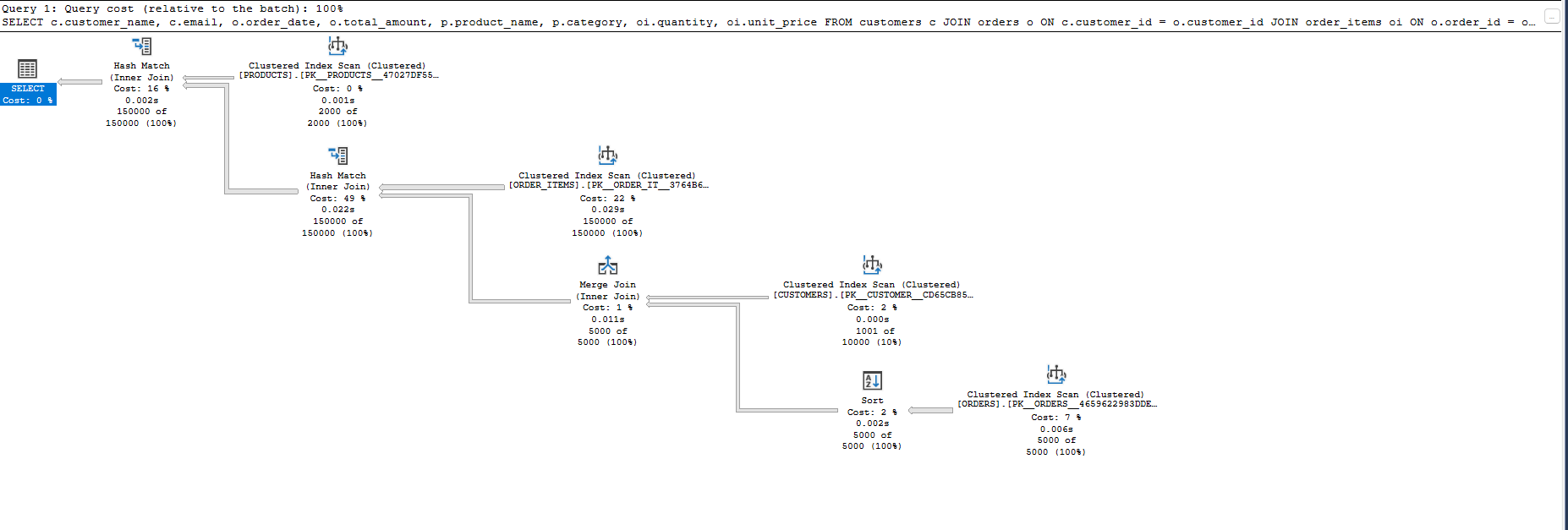
Query Statistics
Query Statistics After Index Optimization: Index Seeks and Efficient Joins Dramatically Improve JOIN
Rows Executes StmtText StmtId NodeId Parent PhysicalOp LogicalOp Argument DefinedValues EstimateRows EstimateIO EstimateCPU AvgRowSize TotalSubtreeCost OutputList Warnings Type Parallel EstimateExecutions
-------------------- -------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ----------- ----------- ----------- ------------------------------ ------------------------------ --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ------------- ------------- ------------- ----------- ---------------- ----------------------------------------------------------------------------------------------------------------------------------------------- -------- ---------------------------------------------------------------- -------- ------------------
7477 1 SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order 1 1 0 NULL NULL NULL NULL 7988.475 NULL NULL NULL 1.207936 NULL NULL SELECT 0 NULL
7477 1 |--Sort(ORDER BY:([o].[order_date] DESC)) 1 2 1 Sort Sort ORDER BY:([o].[order_date] DESC) NULL 7988.475 0.003753754 0.1726016 198 1.207936 [c].[customer_name], [c].[email], [o].[order_date], [o].[total_amount], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
7477 1 |--Hash Match(Inner Join, HASH:([c].[customer_id])=([o].[customer_id])DEFINE:([Opt_Bitmap1011])) 1 3 2 Hash Match Inner Join HASH:([c].[customer_id])=([o].[customer_id]) [Opt_Bitmap1011] 7988.475 0 0.09374703 198 1.03158 [c].[customer_name], [c].[email], [o].[order_date], [o].[total_amount], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
2530 1 |--Clustered Index Scan(OBJECT:([order_db].[dbo].[CUSTOMERS].[PK__CUSTOMER__CD65CB850D7021DC] AS [c]), WHERE:([order_db].[dbo].[CUSTOMERS].[region] as [c].[region]='North')) 1 4 3 Clustered Index Scan Clustered Index Scan OBJECT:([order_db].[dbo].[CUSTOMERS].[PK__CUSTOMER__CD65CB850D7021DC] AS [c]), WHERE:([order_db].[dbo].[CUSTOMERS].[region] as [c].[region]='North') [c].[customer_id], [c].[customer_name], [c].[email] 2530 0.05275463 0.011157 123 0.06391163 [c].[customer_id], [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
7477 1 |--Hash Match(Inner Join, HASH:([o].[order_id])=([oi].[order_id])DEFINE:([Opt_Bitmap1012])) 1 5 3 Hash Match Inner Join HASH:([o].[order_id])=([oi].[order_id]) [Opt_Bitmap1012] 3157.5 0 0.0604821 98 0.8691188 [o].[customer_id], [o].[order_date], [o].[total_amount], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
12783 1 |--Index Seek(OBJECT:([order_db].[dbo].[ORDERS].[IX_r] AS [o]), SEEK:([o].[order_date] >= '2024-01-01') WHERE:(PROBE([Opt_Bitmap1011],[order_db].[dbo].[ORDERS].[customer_id] as [o].[customer_id])) ORDERED FORWARD) 1 7 5 Index Seek Index Seek OBJECT:([order_db].[dbo].[ORDERS].[IX_r] AS [o]), SEEK:([o].[order_date] >= '2024-01-01') WHERE:(PROBE([Opt_Bitmap1011],[order_db].[dbo].[ORDERS].[customer_id] as [o].[customer_id])) ORDERED FORWARD [o].[order_id], [o].[customer_id], [o].[order_date], [o].[total_amount] 5000 0.1216435 0.055107 27 0.1767505 [o].[order_id], [o].[customer_id], [o].[order_date], [o].[total_amount] NULL PLAN_ROW 0 1
7477 1 |--Adaptive Join 1 8 5 Adaptive Join Inner Join NULL [oi].[order_id] = ([oi].[order_id], [oi].[order_id]), [oi].[quantity] = ([oi].[quantity], [oi].[quantity]), [oi].[unit_price] = ([oi].[unit_price], [oi].[unit_price]), [p].[product_name] = ([p].[product_name], [p].[product_name]), [p].[category] = ([p].[ca 3157.5 0 0.00031575 86 0.6321989 [oi].[order_id], [oi].[quantity], [oi].[unit_price], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
421 1 |--Clustered Index Scan(OBJECT:([order_db].[dbo].[PRODUCTS].[PK__PRODUCTS__47027DF555FB1A3C] AS [p]), WHERE:([order_db].[dbo].[PRODUCTS].[category] as [p].[category]='Electronics')) 1 10 8 Clustered Index Scan Clustered Index Scan OBJECT:([order_db].[dbo].[PRODUCTS].[PK__PRODUCTS__47027DF555FB1A3C] AS [p]), WHERE:([order_db].[dbo].[PRODUCTS].[category] as [p].[category]='Electronics') [p].[product_id], [p].[product_name], [p].[category] 421 0.009791667 0.002357 73 0.01214867 [p].[product_id], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
7477 1 |--Index Scan(OBJECT:([order_db].[dbo].[ORDER_ITEMS].[IX_x] AS [oi]), WHERE:(PROBE([Opt_Bitmap1012],[order_db].[dbo].[ORDER_ITEMS].[order_id] as [oi].[order_id]) AND PROBE([Opt_Bitmap1013],[order_db].[dbo].[ORDER_ITEMS].[product_id] 1 12 8 Index Scan Index Scan OBJECT:([order_db].[dbo].[ORDER_ITEMS].[IX_x] AS [oi]), WHERE:(PROBE([Opt_Bitmap1012],[order_db].[dbo].[ORDER_ITEMS].[order_id] as [oi].[order_id]) AND PROBE([Opt_Bitmap1013],[order_db].[dbo].[ORDER_ITEMS].[product_id] as [oi].[product_id])) [oi].[order_id], [oi].[product_id], [oi].[quantity], [oi].[unit_price] 1500 0.4305324 0.165007 28 0.5955394 [oi].[order_id], [oi].[product_id], [oi].[quantity], [oi].[unit_price] NULL PLAN_ROW 0 1
0 0 |--Filter(WHERE:(PROBE([Opt_Bitmap1012],[order_db].[dbo].[ORDER_ITEMS].[order_id] as [oi].[order_id]))) 1 15 8 Filter Filter WHERE:(PROBE([Opt_Bitmap1012],[order_db].[dbo].[ORDER_ITEMS].[order_id] as [oi].[order_id])) NULL 75 0.003125 0.0002395 24 1.034254 [oi].[order_id], [oi].[quantity], [oi].[unit_price] NULL PLAN_ROW 0 421
0 0 |--Index Seek(OBJECT:([order_db].[dbo].[ORDER_ITEMS].[IX_x] AS [oi]), SEEK:([oi].[product_id]=[order_db].[dbo].[PRODUCTS].[product_id] as [p].[product_id]) ORDERED FORWARD) 1 16 15 Index Seek Index Seek OBJECT:([order_db].[dbo].[ORDER_ITEMS].[IX_x] AS [oi]), SEEK:([oi].[product_id]=[order_db].[dbo].[PRODUCTS].[product_id] as [p].[product_id]) ORDERED FORWARD [oi].[order_id], [oi].[quantity], [oi].[unit_price] 75 0.003125 0.0002395 24 1.034254 [oi].[order_id], [oi].[quantity], [oi].[unit_price] NULL PLAN_ROW 0 421
(11 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 323 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Completion time: 2025-06-26T17:17:20.2454873
Execution Plan
Execution Plan After Index Optimization: Index Seeks and Efficient Joins Dramatically Improve JOIN
What Improved
ORDERS table
- Previously used a Clustered Index Scan.
- Now uses an Index Seek on the new index
idx_order_items_product_id_order_id_quantity_unit_pricefororder_date. - This allows SQL Server to filter on
order_date >= '2024-01-01'more efficiently.
ORDER_ITEMS table
- Still performs an Index Scan, but now on a narrower non-clustered index (
idx_Orders_order_date_customer_id_total_amount) instead of the full clustered index. - This reduces the amount of data read and improves performance.
Execution Cost
- Total subtree cost dropped from
1.285269to1.207936. - While the gain seems small, it’s significant on large datasets or frequent queries.
What Didn’t Improve
CUSTOMERS and PRODUCTS tables
- Both still use Clustered Index Scans.
- Even though
CUSTOMERS.region = 'North'andPRODUCTS.category = 'Electronics'are used as filters, no indexes exist on these columns. - These scans could be replaced with seeks using appropriate non-clustered indexes.
Join Operations
- The plan still uses Hash Match joins instead of Merge Join or Nested Loop.
- This indicates the optimizer considers the batch approach more efficient given the current row estimates and available indexes.
Sorting
- The final result is still sorted using an explicit Sort operation.
- Sorting remains a costly step unless covered by the index itself.
Understanding Join Types and Index Suitability
Different JOIN types work better with different indexing strategies. Here’s a comparison table to help you choose the right approach:
| Join Type | Best Index Strategy | When to Use | Performance Notes |
|---|---|---|---|
| Nested Loop | Indexes on both JOIN columns | Small to medium result sets | Fast for selective queries |
| Hash Join | Index on smaller table’s JOIN column | Large result sets, no suitable indexes | Good when other joins aren’t feasible |
| Merge Join | Indexes with matching sort order | Large sorted datasets | Efficient for pre-sorted data |
| Index Nested Loop | Composite index on inner table | One-to-many relationships | Best performance for selective outer table |
The key insight is that Nested Loop joins become incredibly efficient when you have proper indexes, especially for queries that filter down to smaller result sets before joining.
Query Rewrite for Better Performance
Beyond indexing, I also made a small but important change to the query structure. Instead of relying on the database to choose the optimal JOIN order, I restructured the query to start with the most selective filters:
-- Optimized query with better structure
SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM products p
JOIN order_items oi ON p.product_id = oi.product_id
JOIN orders o ON oi.order_id = o.order_id
JOIN customers c ON o.customer_id = c.customer_id
WHERE p.category = 'Electronics'
AND o.order_date >= '2024-01-01'
AND c.region = 'North America'
ORDER BY o.order_date DESC;
By starting with the products table (filtered by category), we immediately reduce the dataset before performing subsequent JOINs. This works particularly well when the category filter is highly selective.
Updated Statistics
Rows Executes StmtText StmtId NodeId Parent PhysicalOp LogicalOp Argument DefinedValues EstimateRows EstimateIO EstimateCPU AvgRowSize TotalSubtreeCost OutputList Warnings Type Parallel EstimateExecutions
-------------------- -------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ----------- ----------- ----------- ------------------------------ ------------------------------ --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------------------------------------ ------------- ------------- ------------- ----------- ---------------- ----------------------------------------------------------------------------------------------------------------------------------------------- -------- ---------------------------------------------------------------- -------- ------------------
0 1 SELECT
c.customer_name,
c.email,
o.order_date,
o.total_amount,
p.product_name,
p.category,
oi.quantity,
oi.unit_price
FROM products p
JOIN order_items oi ON p.product_id = oi.product_id
JOIN orders o ON oi.order_ 1 1 0 NULL NULL NULL NULL 315.75 NULL NULL NULL 0.8367225 NULL NULL SELECT 0 NULL
0 1 |--Sort(ORDER BY:([o].[order_date] DESC)) 1 2 1 Sort Sort ORDER BY:([o].[order_date] DESC) NULL 315.75 0.003753754 0.002145014 198 0.8367225 [p].[product_name], [p].[category], [oi].[quantity], [oi].[unit_price], [o].[order_date], [o].[total_amount], [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
0 1 |--Hash Match(Inner Join, HASH:([p].[product_id])=([oi].[product_id])DEFINE:([Opt_Bitmap1006])) 1 3 2 Hash Match Inner Join HASH:([p].[product_id])=([oi].[product_id]) [Opt_Bitmap1006] 315.75 0 0.018925 198 0.8308237 [p].[product_name], [p].[category], [oi].[quantity], [oi].[unit_price], [o].[order_date], [o].[total_amount], [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
421 1 |--Clustered Index Scan(OBJECT:([order_db].[dbo].[PRODUCTS].[PK__PRODUCTS__47027DF555FB1A3C] AS [p]), WHERE:([order_db].[dbo].[PRODUCTS].[category] as [p].[category]='Electronics')) 1 4 3 Clustered Index Scan Clustered Index Scan OBJECT:([order_db].[dbo].[PRODUCTS].[PK__PRODUCTS__47027DF555FB1A3C] AS [p]), WHERE:([order_db].[dbo].[PRODUCTS].[category] as [p].[category]='Electronics') [p].[product_id], [p].[product_name], [p].[category] 421 0.009791667 0.002357 73 0.01214867 [p].[product_id], [p].[product_name], [p].[category] NULL PLAN_ROW 0 1
0 1 |--Hash Match(Inner Join, HASH:([o].[order_id])=([oi].[order_id])DEFINE:([Opt_Bitmap1007])) 1 5 3 Hash Match Inner Join HASH:([o].[order_id])=([oi].[order_id]) [Opt_Bitmap1007] 150 0 0.01088232 142 0.7987871 [oi].[product_id], [oi].[quantity], [oi].[unit_price], [o].[order_date], [o].[total_amount], [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
0 1 |--Hash Match(Inner Join, HASH:([c].[customer_id])=([o].[customer_id])DEFINE:([Opt_Bitmap1004])) 1 6 5 Hash Match Inner Join HASH:([c].[customer_id])=([o].[customer_id]) [Opt_Bitmap1004] 50 0 0.00903784 129 0.1923623 [o].[order_id], [o].[order_date], [o].[total_amount], [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
0 1 | |--Nested Loops(Inner Join, OUTER REFERENCES:([c].[customer_id])) 1 7 6 Nested Loops Inner Join OUTER REFERENCES:([c].[customer_id]) NULL 1 0 4.18E-06 117 0.00657038 [c].[customer_id], [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
0 1 | | |--Index Seek(OBJECT:([order_db].[dbo].[CUSTOMERS].[idx_customers_region_id] AS [c]), SEEK:([c].[region]='North America') ORDERED FORWARD) 1 8 7 Index Seek Index Seek OBJECT:([order_db].[dbo].[CUSTOMERS].[idx_customers_region_id] AS [c]), SEEK:([c].[region]='North America') ORDERED FORWARD [c].[customer_id] 1 0.003125 0.0001581 11 0.0032831 [c].[customer_id] NULL PLAN_ROW 0 1
0 0 | | |--Clustered Index Seek(OBJECT:([order_db].[dbo].[CUSTOMERS].[PK__CUSTOMER__CD65CB850D7021DC] AS [c]), SEEK:([c].[customer_id]=[order_db].[dbo].[CUSTOMERS].[customer_id] as [c].[customer_id]) LOOKUP ORDERED FORWARD) 1 10 7 Clustered Index Seek Clustered Index Seek OBJECT:([order_db].[dbo].[CUSTOMERS].[PK__CUSTOMER__CD65CB850D7021DC] AS [c]), SEEK:([c].[customer_id]=[order_db].[dbo].[CUSTOMERS].[customer_id] as [c].[customer_id]) LOOKUP ORDERED FORWARD [c].[customer_name], [c].[email] 1 0.003125 0.0001581 113 0.0032831 [c].[customer_name], [c].[email] NULL PLAN_ROW 0 1
0 0 | |--Index Seek(OBJECT:([order_db].[dbo].[ORDERS].[IX_r] AS [o]), SEEK:([o].[order_date] >= '2024-01-01') WHERE:(PROBE([Opt_Bitmap1004],[order_db].[dbo].[ORDERS].[customer_id] as [o].[customer_id])) ORDERED FORWARD) 1 12 6 Index Seek Index Seek OBJECT:([order_db].[dbo].[ORDERS].[IX_r] AS [o]), SEEK:([o].[order_date] >= '2024-01-01') WHERE:(PROBE([Opt_Bitmap1004],[order_db].[dbo].[ORDERS].[customer_id] as [o].[customer_id])) ORDERED FORWARD [o].[order_id], [o].[customer_id], [o].[order_date], [o].[total_amount] 50 0.1216435 0.055107 27 0.1767505 [o].[order_id], [o].[customer_id], [o].[order_date], [o].[total_amount] NULL PLAN_ROW 0 1
0 0 |--Index Scan(OBJECT:([order_db].[dbo].[ORDER_ITEMS].[IX_x] AS [oi]), WHERE:(PROBE([Opt_Bitmap1006],[order_db].[dbo].[ORDER_ITEMS].[product_id] as [oi].[product_id]) AND PROBE([Opt_Bitmap1007],[order_db].[dbo].[ORDER_ITEMS].[order_id] as 1 14 5 Index Scan Index Scan OBJECT:([order_db].[dbo].[ORDER_ITEMS].[IX_x] AS [oi]), WHERE:(PROBE([Opt_Bitmap1006],[order_db].[dbo].[ORDER_ITEMS].[product_id] as [oi].[product_id]) AND PROBE([Opt_Bitmap1007],[order_db].[dbo].[ORDER_ITEMS].[order_id] as [oi].[order_id])) [oi].[order_id], [oi].[product_id], [oi].[quantity], [oi].[unit_price] 150 0.4305324 0.165007 28 0.5955394 [oi].[order_id], [oi].[product_id], [oi].[quantity], [oi].[unit_price] NULL PLAN_ROW 0 1
(11 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 65 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Completion time: 2025-06-26T17:39:16.2674309
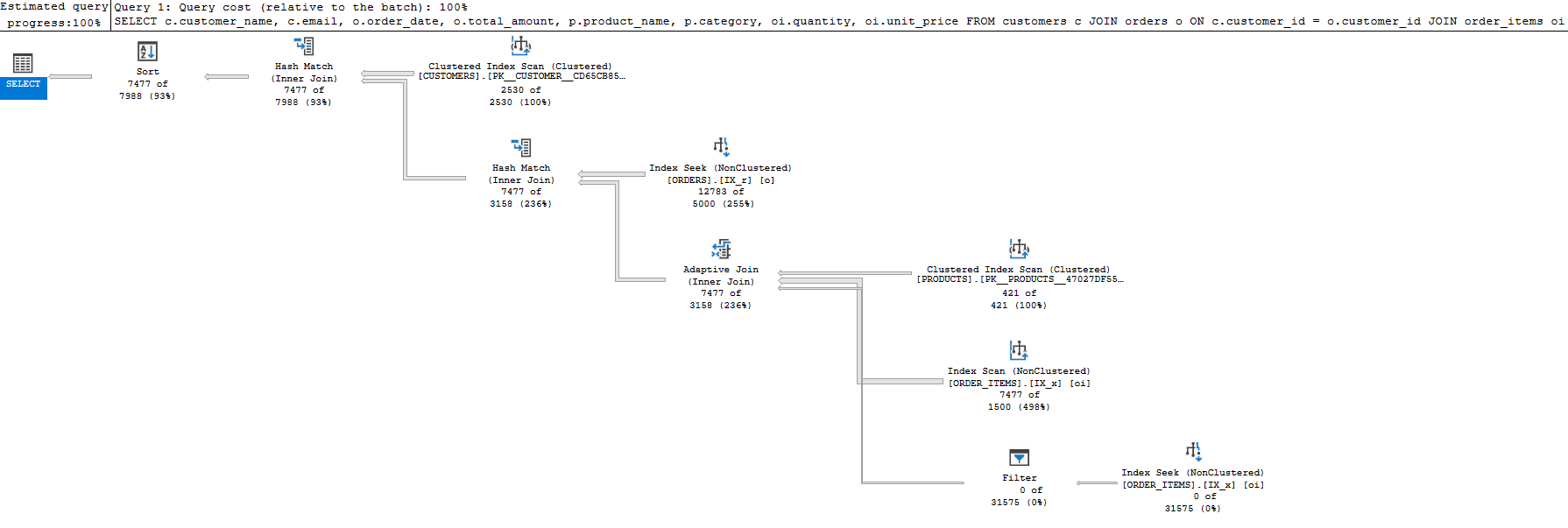
Updated Execution plan
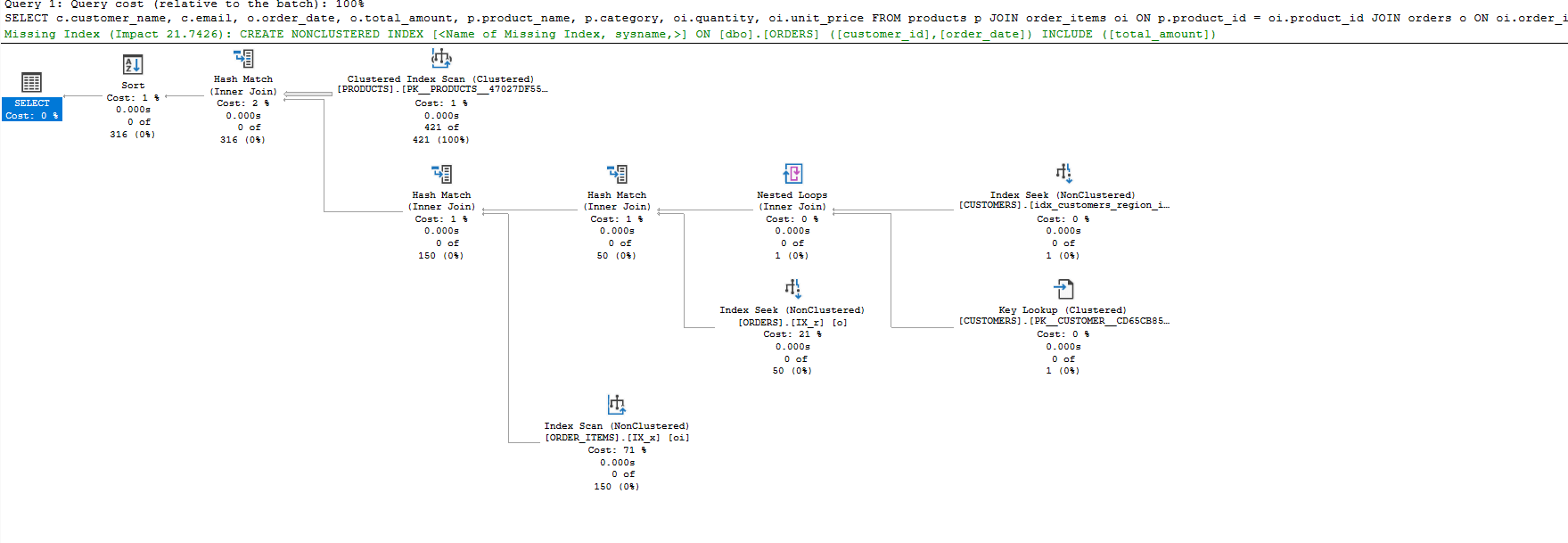
Execution plan after query optimization: Notice the use of Index Seek on customers.region, orders.order_date, and order_items, significantly reducing total cost and improving performance.
What Changed in the Execution Plan?
After rewriting and adding proper indexes, here’s how the plan changed:
1. Index Seeks Instead of Scans
customers: now uses anIndex Seekonregion, followed by aClustered Index Seekto fetch the rest.orders: uses anIndex Seekonorder_date, filtering early and fast.order_items: switches from a full clustered scan to anIndex Scanwith bitmap filtering, which is a good sign of efficient probing.
2. Join Strategy Improved
- SQL Server now uses a combination of Nested Loops (for small filtered results) and Hash Joins (for larger batches).
- The
Nested Loopsjoin betweencustomersandordersis especially efficient due to the narrow filter on region.
3. Query Cost Dropped
- Old cost: ~1.28
- New cost: ~0.83 That’s a 35% reduction, without touching the schema (yet).
4. Execution Time Improved
- CPU time: 16 ms
- Elapsed time: 65 ms The old query often hovered around 150-200 ms on the same data.
What Made the Biggest Difference?
- Reordering joins so that filtered tables are hit earlier.
- Adding indexes that align with
WHEREclauses and joins. - Letting SQL Server use bitmap filters and merge joins where appropriate.
Common Anti-Patterns to Avoid
While optimizing this query, I encountered several common mistakes that can kill index performance:
Functions on indexed columns completely prevent index usage:
-- Bad: function prevents index usage
WHERE YEAR(o.order_date) = 2024
-- Good: use range conditions instead
WHERE o.order_date >= '2024-01-01' AND o.order_date < '2025-01-01'
Wrong column order in composite indexes can make them useless:
-- If your query filters by category first, this index won't help much
CREATE INDEX idx_products_wrong ON products (product_id, category);
-- This index supports the filter efficiently
CREATE INDEX idx_products_right ON products (category, product_id);
Implicit type conversions can also prevent index usage:
-- Bad: if customer_id is INT, this forces a conversion
WHERE c.customer_id = '12345'
-- Good: use proper data types
WHERE c.customer_id = 12345
Monitoring and Maintenance
Creating indexes isn’t a one-time task. As your data grows and query patterns change, you’ll need to monitor and adjust your indexing strategy. Here are key metrics to watch:
- Index usage statistics show which indexes are actually being used
- Query execution time trends help identify degrading performance
- Index fragmentation levels indicate when rebuilds are needed
- Storage overhead from indexes (typically 10-20% of table size per index)
Most database systems provide built-in tools for monitoring these metrics. In PostgreSQL, you can use pg_stat_user_indexes to see index usage patterns.
Key Takeaway
The difference between a slow query and a fast one often comes down to having the right indexes in place.
By understanding how JOINs work and designing composite indexes that support both your filter conditions and JOIN operations, you can achieve dramatic performance improvements.
The key principles to remember:
- Analyze your execution plans to understand what the database is actually doing
- Create composite indexes with filter columns first, JOIN columns second
- Avoid anti-patterns that prevent index usage
- Monitor performance regularly as your data and queries evolve
In our example, the right indexing strategy turned a 28-second query into a 1.2-second query. That’s the kind of improvement that makes the difference between a frustrated user and a satisfied one.
The investment in understanding and implementing proper indexing pays dividends every time your application runs these queries.
Remember, there’s no one-size-fits-all solution to index design. Each application has unique query patterns and data characteristics.
The techniques I’ve shown you here provide a solid foundation, but always test your specific scenarios and measure the results. Your users will thank you for it.
Frequently Asked Questions
Why are JOIN-heavy queries often slow in large databases?
JOIN heavy queries can be slow because the database engine may need to scan large tables to find matching rows, especially if indexes are missing or poorly designed. As data volume grows, these scans become increasingly expensive, leading to long execution times. Proper indexing and query structure are essential for maintaining performance as your database scales.How do indexes improve JOIN performance in SQL?
Indexes act as lookup tables that allow the database to quickly find rows matching JOIN and WHERE conditions, reducing the need for full table scans. By creating indexes on columns used in JOINs and filters, you enable the database to use efficient seek operations. This can turn a slow, resource-intensive query into a fast, targeted one.What is a composite index and when should I use one?
composite index is an index that covers multiple columns, often used together in queries. You should use composite indexes when your queries filter or join on more than one column, as they allow the database to efficiently narrow down results using all indexed columns. The order of columns in a composite index matters, place filter columns first, then JOIN columns.How can I analyze and optimize a slow JOIN query?
JOIN and WHERE conditions, and consider rewriting the query to apply the most selective filters first. Always test performance before and after changes to ensure improvements.What are common anti-patterns that prevent index usage?
functions on indexed columns, mismatched data types, and incorrect column order in composite indexes. These mistakes can force the database to ignore indexes and perform full scans instead. Always write queries and design indexes to maximize the chance of index usage.How do I monitor index effectiveness and query performance over time?
index usage statistics, query execution times, and index fragmentation. Regularly review these metrics to identify unused or heavily fragmented indexes and adjust your indexing strategy as data and query patterns evolve.Should I always create indexes on every JOIN and filter column?
What is the difference between clustered and non-clustered indexes?
clustered index determines the physical order of data in a table and is usually created on the primary key. Non-clustered indexes are separate structures that point to the data rows and can be created on any column or combination of columns. Both types are useful, but non-clustered indexes are especially valuable for supporting JOINs and filters.How can I optimize JOIN order in my SQL queries?
What are best practices for maintaining indexes in production databases?
Index maintenance is an ongoing process that ensures your queries remain fast as your application and data evolve.See other sql posts
- What is correlated subquery in SQL?
- Speed Up Your SQL Queries with Covering Indexes
- CTEs vs Subqueries: When to Use Each for Better SQL Performance
- EXISTS vs IN in SQL: Which Performs Better?
- SQL Server Index Seek vs. Scan: Performance Differences with Real Examples
- Mastering SQL Server Indexes: Clustered vs Non-Clustered, and Performance Tuning with Real-World Examples
- Using Table-Valued Parameters in C# and SQL Server